Обучение с учителем: Распознавание образов
Основы индуктивного метода
Прежде чем ответить на этот вопрос, следует задать критерий оптимальности. Поскольку нейросети осуществляют статистическую обработку данных, нам следует обратиться к основам математической статистики - индуктивному методу.
Байесовский подход
Основная проблема статистики - обобщение эмпирических данных. В формализованном виде задача состоит в выборе наилучшей модели (гипотезы, объясняющей наблюдаемые данные) из некоторого доступного множества. Для решения этой задачи надо уметь оценивать степень достоверности той или иной гипотезы. Математическая формулировка этого подхода содержится в знаменитой теореме Байеса.
Обозначим весь набор имеющихся данных 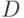 , а гипотезы, объясняющие эти данные (в нашем случае - нейросети), как
, а гипотезы, объясняющие эти данные (в нашем случае - нейросети), как 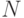 . Предполагается,
что каждая такая гипотеза объясняет данные с большей или меньшей степенью вероятности
. Предполагается,
что каждая такая гипотеза объясняет данные с большей или меньшей степенью вероятности 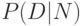 . Теорема Байеса дает решение обратной
задачи - определить степень достоверности гипотез
. Теорема Байеса дает решение обратной
задачи - определить степень достоверности гипотез 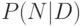 , исходя из их успехов в объяснении данных. Согласно этой теореме, достоверность
гипотезы пропорциональна ее успеху, а также ее априорной вероятности,
, исходя из их успехов в объяснении данных. Согласно этой теореме, достоверность
гипотезы пропорциональна ее успеху, а также ее априорной вероятности, 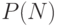 , известной из других соображений, не относящихся к данной
серии наблюдений:
, известной из других соображений, не относящихся к данной
серии наблюдений:
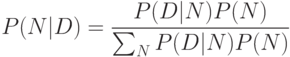
Наилучшая модель определяется максимизацией или ее логарифма, что дает один и тот же результат в силу монотонности
логарифмической функции. Логарифмы удобны тем, что произведение вероятностей независимых событий они переводят в сумму их логарифмов:
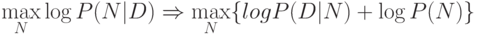 |
( 1) |
Выписанная выше формула является базовой для понимания основ обучения нейросетей, т.к. она задает критерий оптимальности обучения, к которому надо стремиться. Мы еще неоднократно вернемся к ней на протяжении этой лекции. Обсудим, прежде всего значение обоих членов в правой части полученного выражения.
Принцип максимального правдоподобия (maximum likelihood)
Заметим, прежде всего, что второй член в правой части выражения не зависит от данных. Первый же, отражающий эмпирический опыт, как правило, имеет вид колокола тем более узкого, чем больше объем имеющихся в распоряжении данных (см. рисунок 3.4).
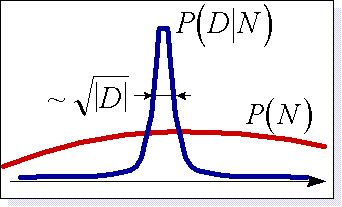
Рис. 3.4. Качественная зависимость априорной и эмпирической составляющих формулы Байеса. Чем больше данных - тем точнее можно выбрать проверяемую гипотезу
Действительно, чем больше данных - тем точнее могут быть проверены следствия конкурирующих гипотез, и, следовательно, тем точнее будет выбор наилучшей.
Следовательно, при стремлении количества данных к бесконечности, последним членом можно пренебречь. Это приближение:
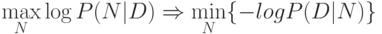
Отрицательный логарифм вероятности имеет смысл эмпирической ошибки при подгонке данных с помощью имеющихся в модели свободных параметров.
Например, в задаче аппроксимации функций обычно предполагается, что данные порождаются некоторой неизвестной функцией, которую
и надо восстановить, но их "истинные" значения искажены случайным гауссовым шумом. Таким образом, условная вероятность набора
данных 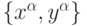 для модели
для модели 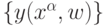 , зависящей от настраиваемых параметров w, имеет гауссово распределение:
, зависящей от настраиваемых параметров w, имеет гауссово распределение:
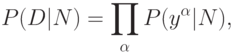
![P(y^\alpha|N)\infty exp[-(y^\alpha-y(y^\alpha|N))^2/2\sigma^2].](/sites/default/files/tex_cache/454bef6b2747d710373844154f4e9ee0.png)
Отрицательный логарифм, таким образом, пропорционален сумме квадратов, и аппроксимация функции сводится к минимизации среднеквадратичной ошибки:

Принцип минимальной длины описания (minimum description length)
В случае нейросетевого моделирования число параметров, как правило, велико, более того, размер сети, как правило, соотносится с объемом обучающей выборки, т.е. число параметров зависит от числа данных. В принципе, как отмечалось ранее, взяв достаточно большую нейросеть, можно приблизить имеющиеся данные со сколь угодно большой точностью. Между тем, зачастую это не то, что нам надо. Например, правильная аппроксимация зашумленной функции по определению должна давать ошибку - порядка дисперсии шума.
Учет второго члена формулы (1) позволяет наложить необходимые ограничения на сложность модели, подавляя, например, излишнее количество настроечных параметров. Смысл совместной оптимизации эмпирической ошибки и сложности модели дает принцип минимальной длины описания.
Согласно этому принципу следует минимизировать общую длину описания данных с помощью модели и описания самой модели. Чтобы увидеть это перепишем формулу (1) в виде:

Первый член, как мы убедились, есть эмпирическая ошибка. Чем она меньше - тем меньше бит потребуется для исправления предсказаний модели. Если модель предсказывает все данные точно, длина описания ошибки равна нулю. Второй член имеет смысл количества информации, необходимого для выбора конкретной модели из множества с априорным распределением вероятностей P(N).
Очень сильный результат теории индуктивного вывода, принадлежащий Рисанену, ограничивает ожидаемую ошибку модели на новых данных степенью сжатия информации с помощью этой модели. Чем меньше описанная выше суммарная длина описания, тем надежнее предсказания такой модели.
Этот вывод пригодится нам позднее - для выбора оптимального размера нейросетей. Пока же предположим, что цель обучения
сформулирована - имеется подлежащий минимизации функционал ошибки 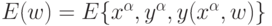 , зависящий от всех настроечных весов нейросети. Наша ближайшая
задача - понять каким образом можно найти значения этих весов, минимизируещих такой функционал.
, зависящий от всех настроечных весов нейросети. Наша ближайшая
задача - понять каким образом можно найти значения этих весов, минимизируещих такой функционал.