
|
есть желание заново пройти курс "Тестирование в современном высшем образовании"
|
Инспектор
Вы можете этот курс.
Опубликован: 30.11.2014 | Уровень: для всех | Доступ: платный | ВУЗ: Кабардино-Балкарский государственный университет
Лекция 5:
Обоснование качества теста
5.2. Задачи и алгоритмы оценки
Рассмотрим некоторые базовые понятия и задачи (алгоритмы) проведения оценивания по любой методологии. Сам класс таких задач – весьма широк.
Задача 1. Пусть даны результаты тестирования группы, состоящей из n испытуемых для заданного теста из m различных знаний. Обычно эти данные представляются в виде некоторой матрицы A баллов размерности n на m:
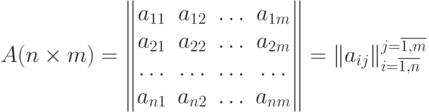
Элемент aij матрицы A представляет собой результат выполнения j-го задания для i-го тестируемого.
Необходимо на основе имеющихся результатов x1, x2, ..., xn тестирования для каждого из n тестированных, вычислить основные статистические показатели тестирования (оценить "сырые" результаты) для выбранной случайным образом группы тестированных.
Алгоритм решения этой задачи состоит из следующих этапов.
- Упорядочиваем ряд по возрастанию (находим генеральную совокупность): x1<x2<...> xn.
- Выбираем интересующее нас подмножество тестированных (выборку).
- Находим среднее арифметическое по выборке
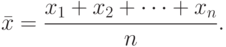
- Находим величины, характеризующие структурные изменения, например, моду и медиану. Для данных, имеющих "хорошее поведение", медиана всегда лежит в промежутке между средним арифметическим и модой. Эти величины выстраиваются по возрастанию следующим образом: среднее, медиана, мода, или же в обратном порядке. Прямой или обратный порядок их расположения можно определить, вычислив так называемый коэффициент асимметрии:Этот коэффициент отражает относительную изменчивость данных.
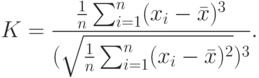
- Находим меры рассеяния, разброса или вариации, показывающие, как остальные элементы совокупности (выборки) группируются около средних величин. Например,
- размах
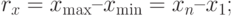
- среднее абсолютное отклонение
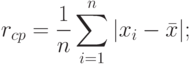
- среднеквадратичное отклонение
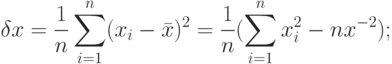
- дисперсия
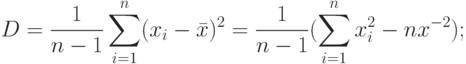
- стандартное отклонение:

- коэффициент вариации
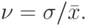
- размах
- Конец алгоритма.
Задача 2. Даны результаты тестирования для каждого из n тестированных и теста длины m в виде матрицы A, а также вектор эталонных ответов B=(b1, b2, …, bm), где bj – эталонный ответ на задание номер j. Необходимо определить "вес" (меру сложности) конкретного задания теста.
Простейший алгоритм решения этой задачи состоит из следующих этапов.
- Определяем для очередного задания теста по матрице А количество тестированных, давших правильный ответ на данное задание.
- В качестве "веса" задания берется дробь cj: знаменатель – количество тестированных, числитель – количество тестированных, давших правильные ответы на все задания.
- Вычисляем смежные веса di: знаменатель – количество всех тестированных, давших неправильный ответ на данное задание номер j, числитель – количество тестированных, давших неправильные ответы на все задания. Иногда в знаменателе берется количество всех тестированных.
- Находится вектор весов выполнения c=(c1, c2, …, cm) для заданного вектора b эталонных ответов.
- Находим вектор весов невыполнения d=(d1, d2, …, dm) для заданного вектора b эталонных ответов.
- Оцениваем дисперсию каждого j-го задания Dj=сidi и стандартное отклонение
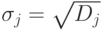 .
. - Конец алгоритма.
Задача 3. Даны результаты тестирования для каждого из n тестированных и теста длины m в виде матрицы A, а также вектор эталонных ответов B=(b1, b2, …, bm), где bj – эталонный ответ на задание номер j. Необходимо оценить валидность каждого задания теста.
Простейший алгоритм решения этой задачи состоит из следующих этапов.
- Определяем для очередного задания теста по матрице A количество тестированных, давших правильный ответ на j-ое задание и находим их средний балл xj.
- Находим аналогично количество тестированных, давших неправильный ответ на j-ое задание и их средний балл yj.
- Находим дробь cj: знаменатель – количество тестированных, давших правильный ответ на данное задание номер j, числитель – количество тестированных.
- Находим дробь di: знаменатель – количество тестированных, давших неправильный ответ на данное задание номер j, числитель – количество тестированных.
- Оцениваем дисперсию каждого j-го задания Dj=сidi и стандартное отклонение .
- Находим стандартное отклонение
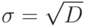 по всему тесту.
по всему тесту. - Находим коэффициент корреляции (меру валидности задания):
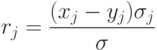
- Если rj>0,3, то задание считаем валидным, иначе – не валидным (с точки зрения критериальной валидности, задания, выполненные всеми или невыполненные никем, не являются валидными).
- Конец алгоритма.
Задача 4. Даны результаты нормативно-ориентированного тестирования для каждого из n тестированных и теста длины m в виде матрицы A, а также вектор эталонных ответов B=(b1, b2, …, bm), где bj – эталонный ответ на задание номер j. Необходимо оценить надежность теста (степень устойчивости результатов тестирования каждого испытуемого, если тестирование было проведено в совершенно одинаковых условиях).
Для вычисления надежности нормативно-ориентированного теста используем коэффициент корреляции между результатами двух параллельных тестов. Сравнивая коэффициенты корреляции, делаем заключение о надежности (внутренней) теста. Если две половины теста коррелированы, то и тест надёжен; в противном случае – не надёжен (или необходимо применить другой, более тонкий математический аппарат исследования надежности).
Простой алгоритм решения этой задачи состоит из следующих этапов.
- Делим тест на две равные части X и Y, например, по четным и нечетным номерам заданий. Этот метод называется методом расщепления теста. Таким образом, мы имеем данные по двум параллельным тестам X и Y – индивидуальные баллы (x1, x2, …, xn), (y1, y2, …, yn), где n – количество тестированных.
- Для каждого задания группы X выполняем предыдущий алгоритм.
- Для каждого задания группы Y выполняем предыдущий алгоритм.
- Находим коэффициент корреляции X и Y по формуле:
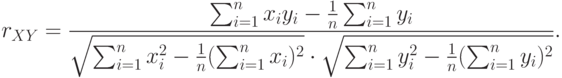
- Находим надежность r всего теста по формуле (Спирмена-Брауна):
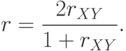
- Конец алгоритма.
Задача 5. Необходимо на основе имеющихся результатов тестирования (матрица А) получить для каждого из n тестированных интегральный (обобщенный) показатель выполнения теста длины m, а затем по вычисленным значениям этого интегрального показателя разбить всех тестированных на заданное количество k групп.
Алгоритм решения этой задачи состоит из следующих этапов.
- Если для j-го задания увеличение значений результатов измерения свидетельствует об улучшении соответствующего свойства, то с ним свяжем признак zj=1, а если свидетельствует об ухудшении – признак zj=–1.
- Выполняем нормирование элементов исходной матрицы так, чтобы в каждом столбце они изменялись в "одном направлении": для каждого задания (при фиксированном j=1, 2, …, m) и для каждого испытуемого i=1, 2, …, n вычислим новое значениегде Mj, mj – наибольшее и наименьшее значения элементов j-го столбца и применяем преобразование вида
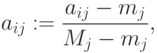
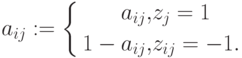
- Для каждого столбца полученной новой матрицы А (нормированной) вычисляется среднее квадратичное отклонение по формулегде
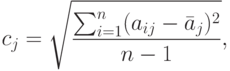
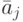 – среднее арифметическое элементов j-го столбца.
– среднее арифметическое элементов j-го столбца. - Вычисляется классификационный интегральный показатель где yi – значение интегрального показателя для i-го обучаемого i=(1,2,…,n), cj – весовой коэффициент j-го задания в тесте или в банке всех заданий, a ij– элемент матрицы А или его преобразованное (нормированное, например, по отношению к максимальному элементу или к норме матрицы).
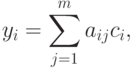
- Находим наименьшее ymin и ymax наибольшее значения интегрального показателя (по всем тестированным). Отрезок [yminymax;] делим на заданное число k интервалов. Часто берут (при построении, например, гистограммы) k=1+3,2lgn. Всех тестированных, для которых вычисленные значения интегрального показателя попадают в один и тот же интервал, отождествляем и относим к одному классу.
- Выдаем результаты: значения интегрального показателя для каждого тестированного, а также его класс (или классификацию тестированных по интегральному показателю).
- Конец алгоритма.
Задача 6. Есть результаты тестирования, полученные в виде матрицы А. Необходимо разбить всех тестированных на несколько групп по отношению к норме (сильные, средние, слабые), где величина x – норма для тестовых результатов и величина k – масштабный коэффициент.
- Ввод данных: n, m, A, k.
- Для каждого из тестированных определяем его суммарный балл:
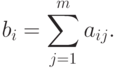
- Разбиваем рассматриваемую выборку тестированных на 3 группы. В первую группу попадают с высокими баллами: суммарный балл для попадающих в эту группу не ниже значения выражения
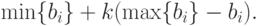
- В третью группу попадают с низкими баллами – не выше значения выражения
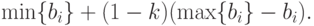
- Во вторую группу попадают все остальные (со средними баллами).
- Выдача результатов: количество и состав попавших в каждую группу.
- Конец алгоритма.
Задача 7. Необходимо отсеять первичные ("сырые") результаты в группах, т.е. по данным x1, x2, …, xn (процент выполнения, валидность и т.д.) выяснить задания (тесты, результаты), которые не согласуются с общей картиной тестирования.
Алгоритм решения задачи состоит из следующих этапов.
- Вычисляется средняя величина
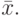
- Вычисляются наибольшее xmax и наименьшее xmin в группе.
- Вычисляются наибольшее отклонение в группе:

- Вычисляется относительное отклонение:
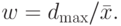
- Находим по таблице распределения Стьюдента процентные точки для t(5%) и t(0.1%). Таблица Стьюдента имеется практически во всех справочниках по математической статистике и в математических пакетах.
- Вычисляем соответствующие точки w(5%;n), w(0.1%;n).
- Если то отсеиваем рассматриваемое данное и пересчитываем все заново (повторяем заново пункты 1-6).

- Конец алгоритма.