Опубликован: 30.05.2023 | Доступ: свободный | Студентов: 840 / 261 | Длительность: 16:08:00
Лекция 3:
Эволюция ИИ в процессе решения практических задач
На рис. 2.9 представлен фрагмент распознаваемого изображения и показано положение фильтра размером 7х7 пикселов над рецептивным полем. Фильтр, показанный на рисунке (он же ядро или матрица весов 7х7), детектирует наличие на изображении кривой, которая задана четырьмя пикселами, расположенными вертикально, и одним по диагонали. На рисунке показан момент, в который матрица находится над элементом изображения, содержащего кривую, подобную искомой. Совпадение ненулевых значений пикселов на фильтре и на рецептивном поле выделено серым цветом.
![Пояснение к процедуре свертки. Источник: по материалам [68]](/EDI/19_10_23_1/1697667598-29580/tutorial/963/objects/2/files/02-09.jpg)
В тот момент, когда фильтр расположен над рецептивным полем, как это показано на рисунке, перемноженные и просуммированные значения дадут в результате число 6600 (см. рис. 2.9).
Из рисунка также видно, что в момент, когда фильтр находился в положении левее на один пиксел, значение свертки равнялось нулю 19При перемещении фильтра (матрицы весов) ее сдвигают на небольшое расстояние в один или несколько пикселей, чтобы не пропустить искомый признак . При перемещении на один пиксел вправо от показанного на рисунке значение свертки увеличится, а потом, при дальнейшем перемещении фильтра вправо (когда он минует границу на исходном изображении), значение свертки опять станет нулевым. Таким образом, перемещая фильтр по всему изображению, мы можем найти все места на изображении, где содержится искомая кривая.
На выходе получается карта признаков, которая дает нам определенную информацию об изображении. Обычно за сверточным слоем следует слой субдискретизации (пулинга). Основная цель этого слоя - уменьшение пространственного размера свернутой карты признаков. Этот слой уменьшает количество параметров на входе, что позволяет снизить вычислительные затраты. Смысл этой операции в том, что, если мы обнаружили некоторый фрагмент изображения, нас перестает интересовать его точное положение с точностью до пиксела - поэтому мы можем заменить некоторую пиксельную окрестность (например, 2x2 или 3x3) одним значением, показывающим, был признак обнаружен в этой окрестности или нет. Как и в случае со сверточным слоем, операция пулинга прогоняет окно по всему полю, и (в зависимости от применяемого метода) на участке заданного размера выбирается максимальное значение (MaxPooling) или вычисляется среднее значение элементов на участке (Average pooling). На рис. 2.8 показан только один сверточный слой и один слой пулинга, на практике их могут быть десятки. На каждом следующем слое операция повторяется, в результате чего карта уменьшается в размере, при том, что количество каналов увеличивается. После прохождения всех слоев свертки и пулинга формируются сотни каналов с признаками, которые интерпретируются как самые абстрактные понятия, выявленные из исходного изображения.
На финальной стадии данные трансформируются в вектор и передаются на обычную полносвязную нейронную сеть (см. рис. 2.8). На выходе мы получаем ответ, в частности в представленном примере с вероятностью 90% сеть распознает изображение как принадлежащее классу "собака".
Компьютерное зрение - это не только классификация
Ранее мы рассмотрели задачу классификации изображений, когда необходимо распознать и присвоить метку объекту (или множеству объектов), присутствующему на изображении, отвечая на вопрос "Что это?". Со временем нейронные сети научились выполнять более сложные задачи, чем классификация изображений, например ИНС, научились выделять на фотографиях контуры объектов, даже если таких экземпляров несколько и они загораживают друг друга.
Сегментация объектов на изображениях подразумевает умение выполнять целый ряд операций (рис. 2.10).
![Основные элементы задачи распознавания объектов. Источник: [69]](/EDI/19_10_23_1/1697667598-29580/tutorial/963/objects/2/files/02-10.jpg)
Локализация объектов подразумевает определение местоположения одного или нескольких объектов на изображении и построение прямоугольной рамки вокруг их границ. Обнаружение объектов объединяет локализацию и классификацию одного или нескольких объектов на изображении (рис. 2.11)
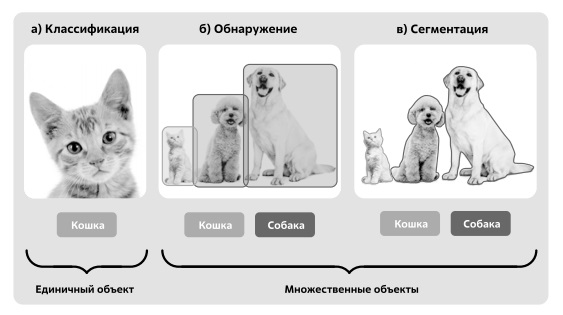
Из рис. 2.11 (б) следует, что модель определила собак как один класс, а кошек как другой, что видно по цвету (тону) рамок. Еще одна задача компьютерного зрения - это сегментация, процесс идентификации похожих объектов, принадлежащих к одному классу, на уровне пикселей, то есть это задача отнесения каждого пикселя изображения к определенному классу: кошка, собака, человек, фон и т. д. (см. рис. 2.11 (в)). Сегментация является базовой технологией, например, для медицинских приложений (идентификация и выделение объектов на снимках) или для автономных автомобилей (идентификация и выделение объектов на дорогах).
Для обучения глубоких нейронных сетей пониманию городской среды используются специализированные наборы данных (датасеты), например такие, как Cityscapes 20Переводится как "Городские пейзажи".
Cityscapes фокусируется на семантической21Различают понятия "semantic segmentation" (семантическая сегментация) - когда на изображении объекты одного класса не отделены друг от друга (показана общая граница пересекающихся объектов) и "instance segmentation" (инстанс сегментация) - когда на изображении пересекающиеся объекты одного класса отделены друг от друга внутренней границей. - Примечание научного редактора сегментации, включает набор городских уличных сцен из пятидесяти городов, сфотографированных в разное время года. Набор данных содержит около 5 тыс. изображений с аннотациями на уровне пикселей и около 20 тыс. частично маркированных изображений.
Существуют соревнования по оценке уровня точности сегментации объектов изображения на базе Cityscapes. Участники оцениваются на основе метрики (IoU - Intersection Over-Union), пересечение над объединением - это метрика для оценки точности модели, которая измеряет правильность предсказания ограничивающего объект контура. IoU - это число, которое количественно определяет степень перекрытия между двумя контурами: области "истины" и области предсказания (рис. 2.12).
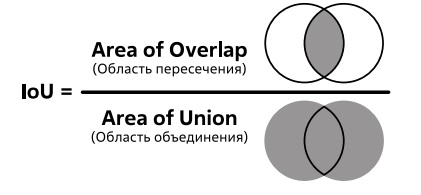
Методика выглядит следующим образом: на обучающем изображении отмечают диапазон обнаруживаемого объекта, затем смотрят на диапазон результатов, полученных по используемому алгоритму, и берут отношение площади пересечения этих областей к площади их объединения. Таким образом, для идеально совпадающих областей получим IoU=1, а для полностью непересекающихся - 0.
В случае семантической сегментации изображения на основе нескольких классов, где на одном изображении могут быть объекты, принадлежащие к разным классам, каждому объекту необходимо присвоить свою метку и соответствующим образом обработать ее при вычислении IoU. Для этого можно найти среднее значение IoU, соответствующее различным классам, которое будет соответствовать фактической степени сходства. Это среднее значение обозначается как средний IoU (Mean IoU - mIoU).
Динамика совершенствования моделей на основе показателя mIoU (по данным соревнования на датасете Cityscape в решении задач семантической маркировки на уровне пикселя) представлена на рис. 2.13.