Опубликован: 30.05.2023 | Доступ: свободный | Студентов: 1256 / 529 | Длительность: 16:08:00
Лекция 3:
Эволюция ИИ в процессе решения практических задач
![Иллюстрация проблемы "долгосрочной зависимости". Источник: [86]](/EDI/18_12_24_2/1734474022-28631/tutorial/963/objects/2/files/02-26.jpg)
А если, предположим, необходимо ответить на вопрос, какое слово должно быть в конце предложения "Я был в Англии, познакомился с массой приятных людей и даже выучил пару фраз на ***"?
Очевидно, что автор предложения выучил несколько фраз на английском, потому что именно это слово упомянуто в начале предложения. Но чем дальше отстоят слова, которые позволяют сделать предсказание искомого слова в последовательности, тем хуже с этой задачей справляется рекуррентная сеть. Это происходит из-за того, что развернутая рекуррентная сеть обучается единым алгоритмом обратного распространения, и ошибка, проходя от конца сети к началу, претерпевает затухание.
Мы отметили, что один из недостатков рекуррентных сетей заключался в "проблеме с долгосрочной зависимостью". Эта проблема была решена при использовании специальных рекуррентных сетей с так называемой долгой краткосрочной памятью, или LSTM (Long short-term memory).
LSTM - это разновидность архитектуры рекуррентных нейронных сетей, способная к обучению долгосрочным зависимостям. LSTM-архитектура способна передавать только релевантную информацию на более глубокие слои сети, позволяя каждому слою "решать", какую информацию нужно сохранить, а какую можно отбросить, что в свою очередь обеспечило возможность фиксировать существенные детали прошлого контекста и сохранять их, пока они актуальны.
Основным недостатком LSTM-архитектуры являлось то, что технология использовала для предсказания только предшествующую информацию. Однако, например, при переводе предложения, чтобы принять правильное решение, важно иметь информацию о словах, использованных во всем предложении. Эта проблема была решена с помощью технологии "двунаправленный LSTM", которая рассматривает полное предложение для предсказания.
В 2014 году в работе Cho и др. [87] была предложена базовая модель sequence-to-sequence - "последовательность в последовательность" (seq2seq) - модель глубокого обучения, основанная на технологии рекуррентных сетей и достигшая больших успехов в задачах NLP и, в частности, в машинном переводе.
Seq2seq - это модель, которая состоит из двух рекуррентных нейронных сетей (RNN): encoder (кодер), которая обрабатывает входные данные, и decoder (декодер), которая генерирует данные вывода. Первая RNN кодирует предложение на исходном языке в так называемый контекстный вектор, вторая декодирует его в последовательность на другом языке, эта схема на новом уровне повторяет уже упомянутую нами ранее схему интерлингва, или межъязыковый перевод.
На рис. 2.27 показана схема машинного перевода с использованием алгоритма Seq2seq.
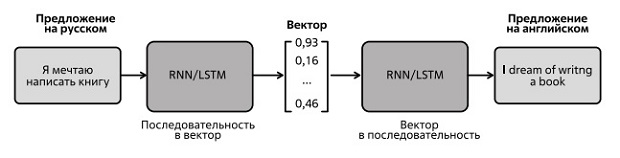
Входная последовательность (предложение на русском языке) обрабатывается кодером, который переводит входную информацию в вектор, называемый контекстом, и пересылает контекст декодеру, который элемент за элементом генерирует выходную последовательность. Заметим, что прежде чем обрабатывать слова, их переводят в векторы с помощью алгоритма эмбеддингов слов, о котором мы рассказали ранее.
RNN и LSTM-сети были весьма популярны в 2014 г., они использовались в машинном переводе, а также в таких популярных продуктах как Сири и Алекса.
В течение нескольких лет RNN и LSTM были основной технологией для задач NLP. Недостатком RNN /LSTM оставалась невысокая точность при переводе длинных фраз, и вскоре им на смену пришел еще более совершенный подход к архитектуре - так называемые "сети внимания". В 2015 году Бахданау и другие [88] предложили механизм внимания как способ устранения указанного недостатка. Механизм внимания позволил декодеру фокусироваться на различных частях входных данных при генерации каждого слова на выходе.
Сети, основанные на внимании, - это тип нейронных сетей, которые позволяют сосредоточиться на определенном подмножестве входных данных. Эти модели показали высокие результаты на многих NLP-задачах, включая машинный перевод и ответы на вопросы.
Сети, основанные на внимании, привнесли способность модели фокусироваться на релевантных входных данных. Модели со вниманием отличались от двунаправленных моделей RNN/LSTM тем, что рассматривали входную последовательность и на каждом шаге решали, какая часть этой последовательности важна и "требует внимания". То есть модель учитывала весомость слов, окружающих текущий контекст. Сети, основанные на внимании, стали популярны в 2015-2016 годах.
Метод внимания помог повысить точность, однако он столкнулся с проблемой в плане производительности. Поскольку вычисления выполнялись последовательно, было трудно масштабировать это решение.
Трансформеры
В 2017 году был представлен новый тип нейронной сети на основе внимания, получивший название "трансформер". Как и RNN, трансформер представляет собой архитектуру для преобразования одной последовательности в другую с помощью механизма кодердекодер, но он отличается от предыдущих существующих моделей Seq2Seq тем, что не использует никаких рекуррентных сетей.
Ранее в курсе как достоинство рекуррентных сетей была отмечена возможность обработки последовательностей "слово за словом". Основным недостатком этой методики является тот факт, что обработка данных занимает много вычислительных ресурсов. Одна из задач разработчиков модели Transformer состояла в том, чтобы устранить этот недостаток. Разработчики пришли к идее обрабатывать всю входную последовательность сразу.
Механизм внимания позволил трансформерам обрабатывать все элементы одновременно за счет формирования прямых связей между отдельными элементами. Благодаря этому модель Transformer смогла обучаться быстрее и на гораздо большем количестве данных с помощью распараллеливания, что в свою очередь повысило точность при выполнении NLP-задач.
Центральным в архитектуре трансформеров является механизм внутреннего внимания (или самовнимания, self-attention), который моделирует отношения между всеми словами в предложении и оценивает, как каждое слово в предложении связано с другими словами [89].
Подробное описание механизма внутреннего внимания выходит за рамки обзорного изложения материалов, принятого в данной курсе. Заметим лишь, что при высокоуровневом объяснении механизма внутреннего внимания обычно говорят, что данный механизм позволяет смоделировать "понимание" связей отдельных слов с другими словами при обработке каждого конкретного слова.
При восприятии текста человек понимает смысл прочитанного, в том числе исходя из понимания смысла слов. Так, например, прочитав две фразы - " кошка не перешла улицу, так как она слишком устала" и "кошка не перешла улицу, потому что она была слишком широкой", - человек сразу понимает, что в первом случае слово "она" относится к слову "кошка", а во втором случае "она" относится к улице.
В рассмотренном примере механизм внутреннего внимания - это тот механизм, который позволяет установить ассоциации между словами "она" со словом "кошка" в первом случае и со словом "улица" во втором случае.
Трансформеры продемонстрировали свои возможности в обработке естественного языка, включая задачи машинного перевода (рис. 2.28) и распознавания речи.