Опубликован: 30.05.2023 | Доступ: свободный | Студентов: 1256 / 529 | Длительность: 16:08:00
Лекция 3:
Эволюция ИИ в процессе решения практических задач
![Упрощенная схема машинного перевода с использованием архитектуры трансформер. Источник: [90]](/EDI/18_12_24_2/1734474022-28631/tutorial/963/objects/2/files/02-28.jpg)
Рис. 2.28. Упрощенная схема машинного перевода с использованием архитектуры трансформер. Источник: [90]
Трансформерные архитектуры привели к фундаментальным изменениям в области компьютерной лингвистики, в которой в течение многих лет доминировали рекуррентные нейронные сети. Появились разные реализации трансформаторов, такие как BERT, GPT, GPT-2, GPT-3.
Возможность большего распараллеливания во время обучения позволила проводить обучение на больших наборах данных. Это привело к развитию трансферного обучения в области языкового моделирования и появлению предварительно обученных моделей.
Напомним, что суть трансферного обучения состоит в том, что навыки, полученные водном "проекте", можно передать в другой (рис.2.29).
![Процесс традиционного и трансферного обучения. Источник: [91]](/EDI/18_12_24_2/1734474022-28631/tutorial/963/objects/2/files/02-29.jpg)
Можно привести аналогию. Когда ребенок впервые пробует кататься на велосипеде, ему нужно учиться с нуля, и это требует определенного времени - необходимо научиться держать равновесие, рулить, тормозить. Когда ребенок подрастает и учится ездить на мотоцикле, ему уже не нужно начинать с нуля. Базовые навыки (такие как умение держать равновесие при вхождении в поворот) уже являются привычными.
Применительно к задачам NLP можно сказать, что суть трансферного обучения заключается в предварительном обучении модели на большом корпусе обычных текстов, из которых модель понимает базовые принципы устройства языка и последующего обучения модели на специфическом в контексте решения задачи корпусе текста, на котором модель дообучается решению конкретной задачи. Это позволяет демонстрировать более высокие результаты, чем в случае обучения на одних только специфических для задачи данных. Успехи трансферного обучения были продемонстрированы на примере таких известных моделей как GPT и BERT.
В 2018 году компания OpenAI предобучила на большом объеме текста генеративную нейронную сеть GPT. На основе разработки от OpenAI в конце 2018 года в Google создали свою нейросеть - BERT, которая сразу побила несколько рекордов по успешности решения ряда NLP-задач.
Модель появилась в начале 2018-го, а уже в октябре того же года Google встроил модель в свой поисковик. Разработчики модели выложили в открытый доступ код модели и сделали возможным скачивание различных версий BERT, переобученных на больших наборах данных. То есть базовая версия модели, которая прошла длительное предобучение на больших корпусах текстов, стала доступной для того, чтобы ее можно было дообучить на прикладных задачах сторонних пользователей. То, что исходный код BERT находился в открытом доступе, позволило множественным разработчикам использовать модель, адаптируя ее к своим уникальным задачам.
Тонкая настройка или дополнительное обучение модели на отдельном наборе данных, отличном от того, на котором модель обучалась изначально, позволяет, слегка изменив параметры сети, обеспечить решение новой задачи - получить более быстрое обучение, чем, если бы та же модель обучалась с нуля.
Тем, кому индивидуальная тонкая настройка была не нужна, было доступно множество открытых бесплатных, предварительно обученных моделей BERT для различных случаев использования, для конкретных задач, таких как анализ настроений в Twitter, категоризатор эмоций, перевод речи в текст, обнаружение токсичных комментариев и т. п. [92].
Вскоре после появления BERT вышла его мультиязычная версия, обученная на 104 языках, в том числе на русском. Обучением русскоязычных моделей BERT занималась лаборатория глубокого обучения МФТИ в рамках проекта Deep Pavlov, Институт исследования искусственного интеллекта AIRI и Sber AI 29Следует упомянуть заслуги команды Сергея Маркова из SberDevices, который с командой обучил ru-GPT3, ru-DALLE и ряд других проектов. - Примечание научного редактора .
Тренды последних лет - мультимодальность, базисные модели
Появление трансформеров привело к радикальным изменениям в мультимодальных задачах, когда одновременно используется несколько типов входных сигналов (например, текст и изображения 30Это не обязательно текст и картинки. Может быть любая пара (и не только пара) типов сигналов. - Примечание научного редактора ).
Длительное время стандартом де-факто для мультимодальных задач с использованием текстов и картинок было применение сверточных нейронных сетей для извлечения признаков из визуальной области, при том, что для получения текстового представления использовались рекуррентные нейронные сети. Эта картина изменилась с появлением архитектуры трансформеров.
В феврале 2019 г. компанией OpenAI была создана модель Generative Pretrained Transformer 2 (GPT-2) - система ИИ с открытым исходным кодом, которая позволяла переводить, отвечать на вопросы и генерировать текст на уровне, который в ряде случаев неотличим от написанного человеком. GPT-2 был создан как развитие модели OpenAI GPT от 2018 года, с десятикратным увеличением как количества параметров, так и размера обучающего набора данных (модель обучили на 40 Гб текста).
В 2020 году OpenAI выпустила модель GPT-3, которая позволяла не только создавать текст, но и генерировать код, писать рассказы и сочинять стихи31Следует отметить, что, строго говоря, никакая модель еще не научилась писать рассказы и полноценные стихи (только хокку). Но главное достижение GPT-3 не в том, что она умеет что-то новое, а то, насколько качественнее она это делает по отношению к GPT-2. Остальные примеры - следствие этого качественного скачка. Для обучения модели потребовалось 570 Гб текста.
Серия моделей GPT также продемонстрировала, что обучение на очень большом корпусе и тонкая настройка модели под целевую задачу могут значительно превзойти обычные модели в качестве, однако, с другой стороны, в полный рост проявилось ограничение, связанное с непропорционально высокой стоимостью обучения больших трансформерных моделей.
Говоря о развитии глубокого обучения в задачах естественного языка интересно провести сравнение последних с развитием моделей, предназначенных для решения задач компьютерного зрения. На рис. 2.30 показан современный период развития нейросетевых моделей для решения задач компьютерного зрения, обработки естественного языка и мультимодальных задач по данным статьи Andrew Shin, Masato Ishii [93].
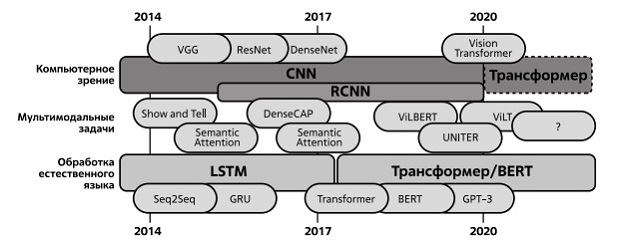
Рис. 2.30. Примеры нейросетевых моделей для решения задач компьютерного зрения, обработки естественного языка и мультимодальных задач. Источник: Andrew Shin, Masato Ishii
В верхней части диаграммы отмечены модели для решения задач компьютерного зрения. Блок, обозначенный как CNN, иллюстрирует совокупность моделей, построенных на архитектуре сверточных сетей. Модели VGG и Resnet уже были нами упомянуты при обсуждении ILSVRC (рис. 2.5). DenseNet - еще одна модель на основе архитектуры сверточных сетей, предложенная в 2017 г. Блок, обозначенный как R-CNN (Region-Based Convolutional Neural Network), - это семейство моделей машинного обучения для компьютерного зрения и, в частности, для обнаружения объектов. Данная архитектура была разработана в 2014 году и включает следующие этапы: нахождение потенциальных объектов на изображении и разбиение их на регионы, извлечение признаков каждого полученного региона с помощью сверточных нейронных сетей, классификация обработанных признаков с помощью метода опорных векторов и уточнение границ регионов с помощью линейной регрессии [94].