
|
Здравствуйте! 4 июня я записалась на курс Прикладная статистика. Заплатила за получение сертификата. Изучала лекции, прошла Тест 1. Сегодня вижу, что я вне курса! Почему так произошло? |
Инспектор
Вы можете этот курс.
Опубликован: 09.11.2009 | Уровень: для всех | Доступ: платный
Лекция 12:
Статистика интервальных данных
12.4. Линейный регрессионный анализ интервальных данных
Перейдем к многомерному статистическому анализу. Сначала с позиций асимптотической математической статистики интервальных данных рассмотрим оценки метода наименьших квадратов (МНК).
Статистическое исследование зависимостей - одна из наиболее важных задач, которые возникают в различных областях науки и техники. Под словами "исследование зависимостей" имеется в виду выявление и описание существующей связи между исследуемыми переменными на основании результатов статистических наблюдений. К методам исследования зависимостей относятся регрессионный анализ, многомерное шкалирование, идентификация параметров динамических объектов, факторный анализ, дисперсионный анализ, корреляционный анализ и др. Однако многие реальные ситуации характеризуются наличием данных интервального типа, причем известны допустимые границы погрешностей (например, из технических паспортов средств измерения).
Если какая-либо группа объектов характеризуется переменными 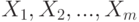 и проведен эксперимент, состоящий из
и проведен эксперимент, состоящий из 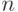 опытов, где в каждом опыте эти переменные измеряются один раз, то экспериментатор получает набор чисел:
опытов, где в каждом опыте эти переменные измеряются один раз, то экспериментатор получает набор чисел: 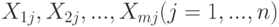 .
.
Однако процесс измерения, какой бы физической природы он ни был, обычно не дает однозначный результат. Реально результатом измерения какой-либо величины 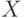 являются два числа:
являются два числа:  - нижняя граница и
- нижняя граница и 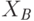 - верхняя граница. Причем
- верхняя граница. Причем ![X_{\textit{ИСТ}}\in [X_{\textit{Н}},X_{\textit{В}}]](/sites/default/files/tex_cache/c14a02178c11bdcf9ba903f0b395a6e9.png) , где
, где  - истинное значение измеряемой величины. Результат измерения можно записать как
- истинное значение измеряемой величины. Результат измерения можно записать как ![X:[X_{\textit{Н}},X_{\textit{В}}]](/sites/default/files/tex_cache/18fbabf5ae82e11436015b4fad737327.png) . Интервальное число может быть представлено другим способом, а именно,
. Интервальное число может быть представлено другим способом, а именно, ![X:[Х_m,\Delta_x]](/sites/default/files/tex_cache/5cf8777beb51966db4e75b08ce85c183.png) , где
, где 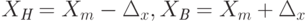 . Здесь
. Здесь 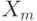 - центр интервала (как правило, не совпадающий с
- центр интервала (как правило, не совпадающий с  ), а
), а 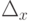 - максимально возможная погрешность измерения.
- максимально возможная погрешность измерения.
Метод наименьших квадратов для интервальных данных. Пусть математическая модель задана следующим образом:
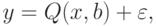
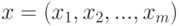 - вектор влияющих переменных (факторов), поддающихся измерению;
- вектор влияющих переменных (факторов), поддающихся измерению; 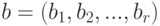 - вектор оцениваемых параметров модели;
- вектор оцениваемых параметров модели; 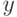 - отклик модели (скаляр);
- отклик модели (скаляр); 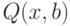 - скалярная функция векторов
- скалярная функция векторов 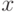 и
и  ; наконец,
; наконец, 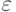 - случайная ошибка (невязка, погрешность).
- случайная ошибка (невязка, погрешность).Пусть проведено опытов, причем в каждом опыте измерены (один раз) значения отклика  и вектора факторов
и вектора факторов  . Результаты измерений могут быть представлены в следующем виде:
. Результаты измерений могут быть представлены в следующем виде:
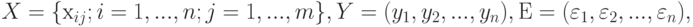 - матрица значений измеренного вектора в опытах;
- матрица значений измеренного вектора в опытах;  - вектор значений измеренного отклика в опытах;
- вектор значений измеренного отклика в опытах; 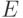 - вектор случайных ошибок. Тогда выполняется матричное соотношение:
- вектор случайных ошибок. Тогда выполняется матричное соотношение:
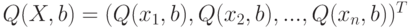 , причем
, причем 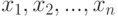 -
- 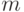 -мерные вектора, которые составляют матрицу
-мерные вектора, которые составляют матрицу  .
.Введем меру близости  между векторами и
между векторами и 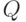 . В МНК в качестве берется квадратичная форма взвешенных квадратов
. В МНК в качестве берется квадратичная форма взвешенных квадратов 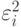 невязок
невязок  , т.е.
, т.е.
![d(Y,Q) = [Y-Q(X,b)]^T W[Y-Q(X,b)],](/sites/default/files/tex_cache/4a156278947681663c6a8ac45de0ab09.png)
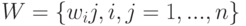 - матрица весов, не зависящая от . Тогда в качестве оценки можно выбрать такое
- матрица весов, не зависящая от . Тогда в качестве оценки можно выбрать такое  , при котором мера близости принимает минимальное значение, т.е.
, при котором мера близости принимает минимальное значение, т.е.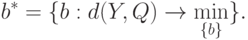
В общем случае решение этой экстремальной задачи может быть не единственным. Поэтому в дальнейшем будем иметь в виду одно из этих решений. Оно может быть выражено в виде 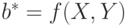 , где
, где  , причем
, причем 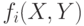 непрерывны и дифференцируемы по
непрерывны и дифференцируемы по 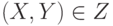 , где
, где 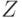 - область определения функции
- область определения функции 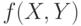 . Эти свойства функции дают возможность использовать подходы статистики интервальных данных.
. Эти свойства функции дают возможность использовать подходы статистики интервальных данных.
Преимущество метода наименьших квадратов заключается в сравнительной простоте и универсальности вычислительных процедур. Однако не всегда оценка МНК является состоятельной (при функции 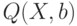 , не являющейся линейной по векторному параметру b), что ограничивает его применение на практике.
, не являющейся линейной по векторному параметру b), что ограничивает его применение на практике.
Важным частным случаем является линейный МНК, когда есть линейная функция от :

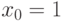 , а
, а 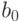 - свободный член линейной комбинации. Как известно, в этом случае МНК-оценка имеет вид:
- свободный член линейной комбинации. Как известно, в этом случае МНК-оценка имеет вид: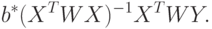
Если матрица 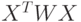 не вырождена, то эта оценка является единственной. Если матрица весов
не вырождена, то эта оценка является единственной. Если матрица весов 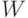 единичная, то
единичная, то
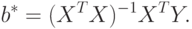
Пусть выполняются следующие предположения относительно распределения ошибок 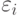 :
:
- ошибки имеют нулевые математические ожидания
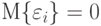 ;
; - результаты наблюдений имеют одинаковую дисперсию
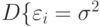 ;
; - ошибки наблюдений некоррелированы, т.е. cov\{\varepsilon_i,\varepsilon_j} = 0.
Тогда, как известно, оценки МНК являются наилучшими линейными оценками, т.е. состоятельными и несмещенными оценками, которые представляют собой линейные функции результатов наблюдений и обладают минимальными дисперсиями среди множества всех линейных несмещенных оценок. Далее именно этот наиболее практически важный частный случай рассмотрим более подробно.
Как и в других постановках асимптотической математической статистики интервальных данных, при использовании МНК измеренные величины отличаются от истинных значений из-за наличия погрешностей измерения. Запишем истинные данные в следующей форме:
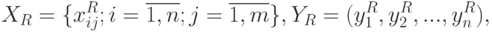
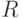 - индекс, указывающий на то, что значение истинное. Истинные и измеренные данные связаны следующим образом:
- индекс, указывающий на то, что значение истинное. Истинные и измеренные данные связаны следующим образом:
 . Предположим, что погрешности измерения отвечают граничным условиям
. Предположим, что погрешности измерения отвечают граничным условиям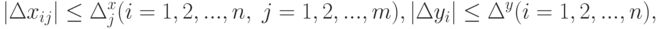 |
( 48) |
Пусть множество возможных значений  входит в - область определения функции . Рассмотрим
входит в - область определения функции . Рассмотрим 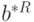 - оценку МНК, рассчитанную по истинным значениям факторов и отклика, и - оценку МНК, найденную по искаженным погрешностями данным. Тогда
- оценку МНК, рассчитанную по истинным значениям факторов и отклика, и - оценку МНК, найденную по искаженным погрешностями данным. Тогда
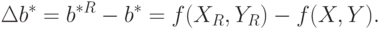
Ввести понятие нотны придется несколько иначе, чем это было сделано выше, поскольку оценивается не одномерный параметр, а вектор. Положим:
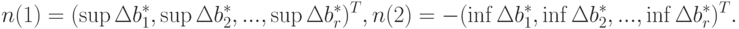
Будем называть 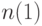 - нижней нотной, а
- нижней нотной, а  - верхней нотной. Предположим, что при безграничном возрастании числа измерений , т.е. при
- верхней нотной. Предположим, что при безграничном возрастании числа измерений , т.е. при 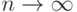 , векторы
, векторы 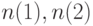 стремятся к постоянным значениям
стремятся к постоянным значениям 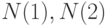 соответственно. Тогда
соответственно. Тогда 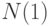 будем называть нижней асимптотической нотной, а
будем называть нижней асимптотической нотной, а 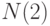 - верхней асимптотической нотной.
- верхней асимптотической нотной.
Рассмотрим доверительное множество 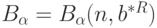 для вектора параметров , т.е. замкнутое связное множество точек в
для вектора параметров , т.е. замкнутое связное множество точек в  -мерном евклидовом пространстве такое, что
-мерном евклидовом пространстве такое, что 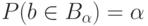 где
где  - доверительная вероятность, соответствующая
- доверительная вероятность, соответствующая 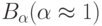 . Другими словами,
. Другими словами, 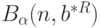 есть область рассеивания (аналог эллипсоида рассеивания) случайного вектора с доверительной вероятностью и числом опытов .
есть область рассеивания (аналог эллипсоида рассеивания) случайного вектора с доверительной вероятностью и числом опытов .
Из определения верхней и нижней нотн следует, что всегда ![b^{*R}\in [b^*-n(1);b^*+n(2)]](/sites/default/files/tex_cache/64df8c8753cba7a772a15a92624e5a14.png) .. В соответствии с определением нижней асимптотической нотны и верхней асимптотической нотны можно считать, что
.. В соответствии с определением нижней асимптотической нотны и верхней асимптотической нотны можно считать, что ![b^{*R}\in [b^*-N(1);b^*+N(2)]](/sites/default/files/tex_cache/7ba5036817399230367c11a2fc6dae6a.png) . при достаточно большом числе наблюдений . Этот многомерный интервал описывает -мерный гиперпараллелепипед
. при достаточно большом числе наблюдений . Этот многомерный интервал описывает -мерный гиперпараллелепипед 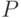 .
.
Каким-либо образом разобьем на 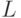 гиперпараллелепипедов. Пусть
гиперпараллелепипедов. Пусть  - внутренняя точка
- внутренняя точка 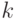 -го гиперпараллелепипеда. Учитывая свойства доверительного множества и устремляя к бесконечности, можно утверждать, что
-го гиперпараллелепипеда. Учитывая свойства доверительного множества и устремляя к бесконечности, можно утверждать, что 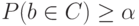 где
где

Таким образом, множество 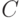 характеризует неопределенность при оценивании вектора параметров . Его можно назвать доверительным множеством в статистике интервальных данных.
характеризует неопределенность при оценивании вектора параметров . Его можно назвать доверительным множеством в статистике интервальных данных.
Введем некоторую меру 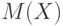 , характеризующую "величину" множества
, характеризующую "величину" множества 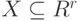 . По определению меры она удовлетворяет условию: если
. По определению меры она удовлетворяет условию: если 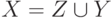 и
и 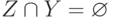 , то
, то 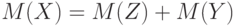 . Примерами такой меры являются площадь для
. Примерами такой меры являются площадь для 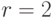 и объем для
и объем для 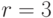 . Тогда:
. Тогда:
 |
( 49) |
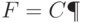 . Здесь
. Здесь 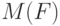 характеризует меру статистической неопределенности, в большинстве случаев она убывает при увеличении числа опытов . В то же время
характеризует меру статистической неопределенности, в большинстве случаев она убывает при увеличении числа опытов . В то же время 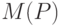 характеризует меру интервальной (метрологической) неопределенности, и, как правило, стремится к некоторой постоянной величине при увеличении числа опытов . Пусть теперь требуется найти то число опытов, при котором статистическая неопределенность составляет
характеризует меру интервальной (метрологической) неопределенности, и, как правило, стремится к некоторой постоянной величине при увеличении числа опытов . Пусть теперь требуется найти то число опытов, при котором статистическая неопределенность составляет 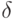 -ю часть общей неопределенности, т.е.
-ю часть общей неопределенности, т.е.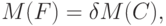 |
( 50) |
 . Тогда, подставив соотношение (50) в равенство (49) и решив уравнение относительно , получим искомое число опытов. В асимптотической математической статистике интервальных данных оно называется "рациональным объемом выборки". При этом есть "степень малости" статистической неопределенности
. Тогда, подставив соотношение (50) в равенство (49) и решив уравнение относительно , получим искомое число опытов. В асимптотической математической статистике интервальных данных оно называется "рациональным объемом выборки". При этом есть "степень малости" статистической неопределенности  относительно всей неопределенности. Она выбирается из практических соображений. При использовании "принципа уравнивания погрешностей" согласно [
[
1.15
]
] имеем
относительно всей неопределенности. Она выбирается из практических соображений. При использовании "принципа уравнивания погрешностей" согласно [
[
1.15
]
] имеем 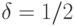 .
.Метод наименьших квадратов для линейной модели. Рассмотрим наиболее важный для практики частный случай МНК, когда модель описывается линейным уравнением (см. выше).
Для простоты описания преобразований пронормируем переменные  . следующим образом:
. следующим образом:
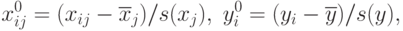
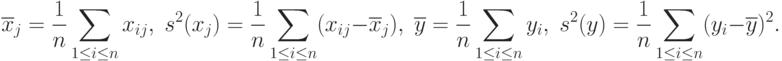
Тогда
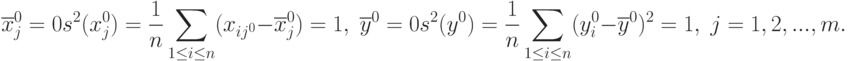
В дальнейшем изложении будем считать, что рассматриваемые переменные пронормированы описанным образом, и верхние индексы 0 опустим. Для облегчения демонстрации основных идей примем достаточно естественные предположения.
1. Для рассматриваемых переменных существуют следующие пределы:
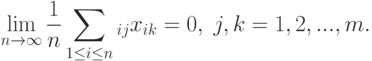
2. Количество опытов n таково, что можно пользоваться асимптотическими результатами, полученными при .
3. Погрешности измерения удовлетворяют одному из следующих типов ограничений:
тип 1. Абсолютные погрешности измерения ограничены согласно (48);
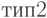 . Относительные погрешности измерения ограничены:
. Относительные погрешности измерения ограничены:
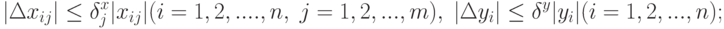
тип 3. Ограничения наложены на сумму погрешностей:
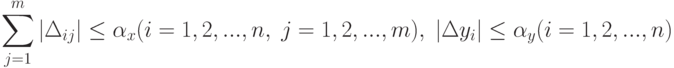
Перейдем к вычислению нотны оценки МНК. Справедливо равенство:

Воспользуемся следующей теоремой из теории матриц [ [ 12.10 ] ].
Теорема. Если функция 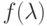 разлагается в степенной ряд в круге сходимости
разлагается в степенной ряд в круге сходимости 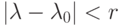 , т.е.
, т.е.

 , характеристические числа которой
, характеристические числа которой 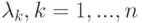 , лежат внутри круга сходимости.
, лежат внутри круга сходимости.Из этой теоремы вытекает, что:

Легко убедиться, что:
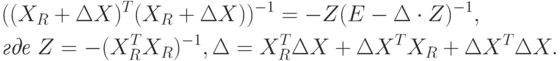
Это вытекает из последовательности равенств:
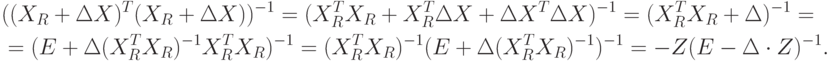
Применим приведенную выше теорему из теории матриц, полагая 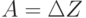 и принимая, что собственные числа этой матрицы удовлетворяют неравенству
и принимая, что собственные числа этой матрицы удовлетворяют неравенству 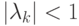 . Тогда получим:
. Тогда получим:
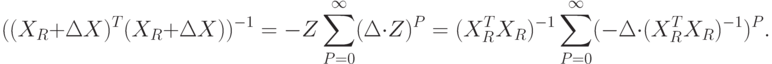
Подставив последнее соотношение в заключение упомянутой теоремы, получим:
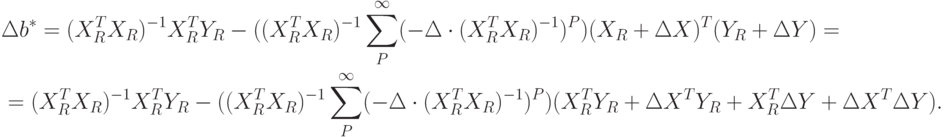
Для дальнейшего анализа понадобится вспомогательное утверждение. Исходя из предположений 1-3, докажем, что:

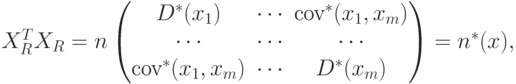
 - состоятельные и несмещенные оценки дисперсий и коэффициентов ковариации. Следовательно,
- состоятельные и несмещенные оценки дисперсий и коэффициентов ковариации. Следовательно,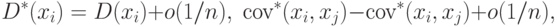
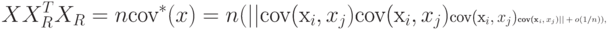
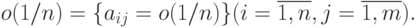
Другими словами, каждый элемент матрицы, обозначенной как  , есть бесконечно малая величина порядка
, есть бесконечно малая величина порядка 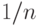 . Для рассматриваемого случая
. Для рассматриваемого случая 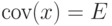 , поэтому
, поэтому

Предположим, что достаточно велико и можно считать, что собственные числа матрицы меньше единицы по модулю, тогда
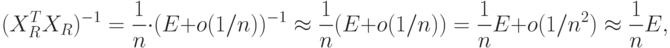
Подставим доказанное асимптотическое соотношение в формулу для приращения , получим
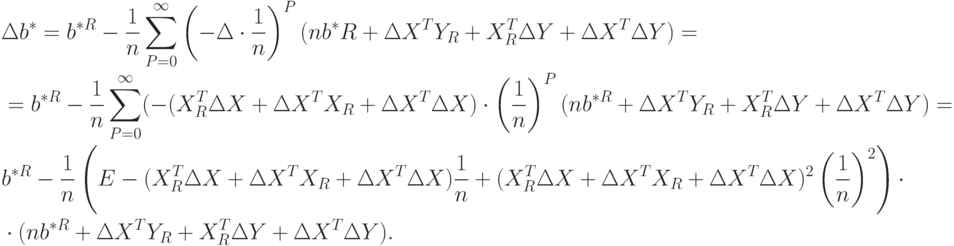
Перейдем от матричной к скалярной форме, опуская индекс (R):
![\begin{aligned}
&\Delta b_k^*=\frac{1}{n}\{\sum_j^m\sum_i^n(x_{ik}\Delta x_{ij}+\Delta x_{ik}x_{ij})b_j^*-\sum_i^n(\Delta x_{ik}y_i+x_{ik}\Delta y_i)\}; \\
&\Delta b_k^*=\frac{1}{n}\{2\sum_i^nx_{ik}\Delta x_{ik}b_k^*+\sum_{j\ne k}^m \sum_i^n [(x_{ik}\Delta x_{ij}+\Delta x_{ik}x_{ij})b_j^*-\sum_{i}^n(\Delta x_{ik}y_i+x_{ik}\Delta y_i)\}= \\
&=\frac{1}{n}\{2\sum_i^nx_{ik}\Delta x_{ik}b_k^*+\sum_{j\ne k}^m \sum_i^n [(x_{ik}\Delta x_{ij}+\Delta x_{ik}x_{ij})b_j^*-\frac{1}{m-1}\Delta x_{ik}y_i]-\sum_i^n x_{ik}\Delta y_i\}= \\
&=\frac{1}{n}\{\sum_{j\ne k}^m \sum_i^n[\frac{2}{m-1}x_{ik}\Delta x_{ik}b_k^*+(x_{ik}\Delta x_{ij}+\Delta x_{ik}x_{ij})b_j^*-\frac{1}{m-1}\Delta x_{ik}y_i]-\sum_i^n x_{ik}\Delta y_i\}= \\
&=\frac{1}{n}\{\sum_{j\ne k}^m \sum_i^n[(\frac{2}{m-1}x_{ik}b_k^*+x_{ij}b_j^*-\frac{1}{m-1}y_i)\Delta x_{ik}-x_{ik}b_j^*\Delta x_{ij}]-\sum_i^n x_{ik}\Delta y_i\}
\end{aligned}](/sites/default/files/tex_cache/974d2f23b7992e742705646dc15d0b15.png)
Будем искать 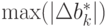 по
по 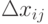 и
и 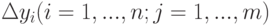 . Для этого рассмотрим все три ранее введенных типа ограничений на ошибки измерения.
. Для этого рассмотрим все три ранее введенных типа ограничений на ошибки измерения.
Тип 1 (абсолютные погрешности измерения ограничены). Тогда:
![\max_{\Delta x,\Delta y}(|\Delta b_k^*|)=\frac{1}{n}
\left\{
\sum_{j\ne k}^m \sum_i^n
\left[\left|\left(
\frac{2}{m-1}x_{ik}b_k^*+x_{ij}b_j^*-\frac{1}{m-1}y_i
\right)
\right|
\Delta_k^x+|x_{ik}b_j^*|\Delta_j^x
\right]
-\sum_i^n |x_{ik}|\Delta y
\right\}.](/sites/default/files/tex_cache/031d9fe35ef76725fd61bcea400c27d1.png)
Тип 2 (относительные погрешности измерения ограничены). Аналогично получим:
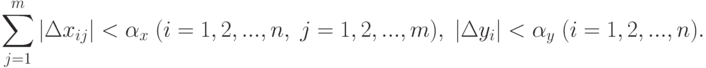
Тип З (ограничения наложены на сумму погрешностей). Предположим, что  достигает максимального значения при таких значениях погрешностей и
достигает максимального значения при таких значениях погрешностей и 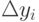 , которые мы обозначим как:
, которые мы обозначим как:
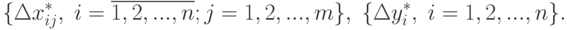
![\max_{\Delta x,\Delta y}(|\Delta b_k^*|)=\frac{1}{n}
\left\{
\sum_{j\ne k}^m \sum_i^n
\left[\left(
\frac{2}{m-1}x_{ik}b_k^*+x_{ij}b_j^*-\frac{1}{m-1}y_i
\right)
x_{ik}^*+x_{ik}b_j^*x_{ij}^*
\right]
-\sum_i^n x_{ik}y_i^*
\right\}.](/sites/default/files/tex_cache/aa964803ec167184f554bf08b708ba32.png)
Ввиду линейности последнего выражения и выполнения ограничения типа 3:
![\begin{aligned}
&\max_{\Delta x,\Delta y}(|\Delta b_k^*|)=\frac{1}{n}
\left\{
\sum_{j\ne k}^m \sum_i^n
\left[\left|
\frac{2}{m-1}x_{ik}b_k^*+x_{ij}b_j^*-\frac{1}{m-1}y_i
\right|\cdot
|\Delta x_{ik}^*|+|x_{ik}b_j^*|\cdot|\Delta x_{ij}^*|
\right]
-\sum_i^n |x_{ik}|\cdot|\Delta y_i^*|
\right\}, \\
&\sum_j^m|\Delta x_{ij}^*|-\alpha_x\quad(j=1,2,...,m),\quad |\Delta y_i^*|=\alpha_y.
\end{aligned}](/sites/default/files/tex_cache/bc03f9c378f54a6a1a364ac4641b79f9.png)
Для простоты записей выкладок сделаем следующие замены:
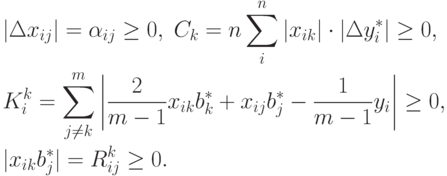
Теперь для достижения поставленной цели можно сформулировать следующую задачу, которая разделяется на типовых задач оптимизации:
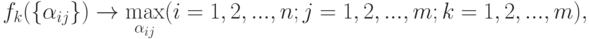
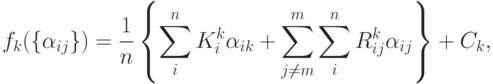

Перепишем минимизируемые функции в следующем виде:
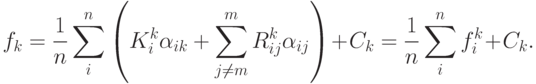
Очевидно, что  .
.
Легко видеть, что
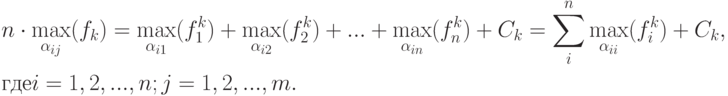
Следовательно, необходимо решить  задач
задач

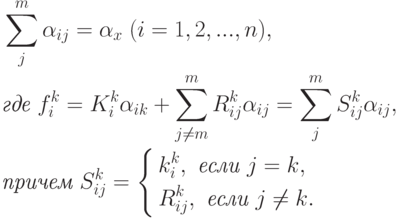
Сформулирована типовая задача поиска экстремума функции. Она легко решается. Поскольку
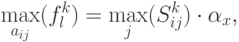
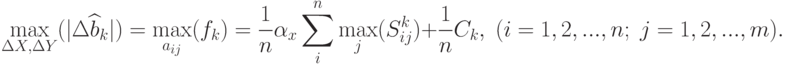
Кроме рассмотренных выше трех видов ограничений на погрешности могут представлять интерес и другие, но для демонстрации типовых результатов ограничимся только этими тремя видами.
Оценивание линейной корреляционной связи. В качестве примера рассмотрим оценивание линейной корреляционной связи случайных величин и 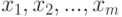 с нулевыми математическими ожиданиями. Пусть эта связь описывается соотношением:
с нулевыми математическими ожиданиями. Пусть эта связь описывается соотношением:
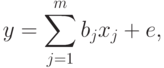
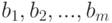 - постоянные, а случайная величина
- постоянные, а случайная величина  некоррелирована с
некоррелирована с 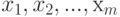 . Допустим, необходимо оценить неизвестные параметры
. Допустим, необходимо оценить неизвестные параметры 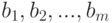 по серии независимых испытаний:
по серии независимых испытаний: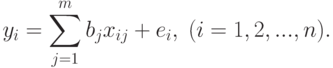
Здесь при каждом 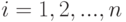 имеем новую независимую реализацию рассматриваемых случайных величин. В этой частной схеме оценки наименьших квадратов
имеем новую независимую реализацию рассматриваемых случайных величин. В этой частной схеме оценки наименьших квадратов 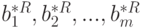 параметров
параметров 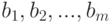 являются, как известно, состоятельными [
[
12.41
]
].
являются, как известно, состоятельными [
[
12.41
]
].
Пусть величины 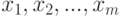 в дополнение к попарной независимости имеют единичные дисперсии. Тогда из закона больших чисел [
[
12.41
]
] следует существование следующих пределов (ср. предположение 1 выше):
в дополнение к попарной независимости имеют единичные дисперсии. Тогда из закона больших чисел [
[
12.41
]
] следует существование следующих пределов (ср. предположение 1 выше):
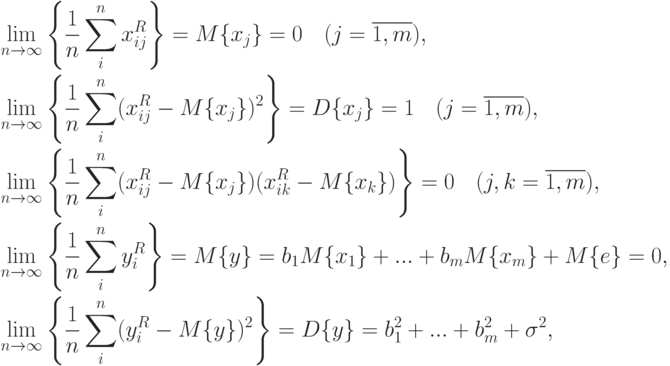
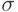 - среднее квадратическое отклонение случайной величины
- среднее квадратическое отклонение случайной величины  .
.Пусть измерения производятся с погрешностями, удовлетворяющими ограничениям типа 1, тогда максимальное приращение величины 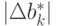 , как показано выше, равно:
, как показано выше, равно:
![\max_{\Delta x,\Delta y}(|\Delta b_k^*|)=\frac{1}{n}
\left\{
\sum_{j\ne k}^m\sum_i^n
\left[\left|
\frac{2}{m-1}x_{ik}^R b_k^*+x_{ij}^R b_j^*-\frac{1}{m-1}y_i^r
\right|
\cdot\Delta_k^x+|x_{ik}^R b_j^*|\cdot\Delta_j^x
\right]
+\sum_i^n|x_{ik}^R|\cdot\Delta y
\right\}.](/sites/default/files/tex_cache/1820e75d3b1c5ebd085e15feb6bb3649.png)
Перейдем к предельному случаю и выпишем выражение для нотны:
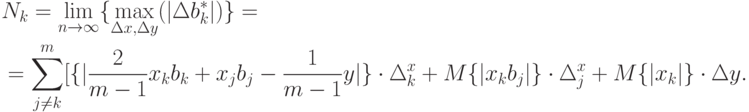
В качестве примера рассмотрим случай  . Тогда
. Тогда

Приведенное выше выражение для максимального приращения метрологической погрешности не может быть использовано в случае 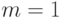 . Для выведем выражение для нотны, исходя из соотношения:
. Для выведем выражение для нотны, исходя из соотношения:

Подставив 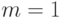 , получим:
, получим:

Следовательно, нотна выглядит так:
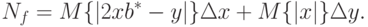
Анастасия Маркова