

| Россия, Ташкент |
Инспектор
Вы можете этот курс.
Опубликован: 23.04.2007 | Уровень: специалист | Доступ: платный | ВУЗ: Московский государственный университет имени М.В.Ломоносова
Лекция 12:
Алгоритмы квантования для полутоновых и цветных изображений
Метод связности графа
Построим матрицу расстояний D между значениями атрибутов исходного изображения. В качестве расстояния можно взять квадрат евклидовой метрики (так же, как и в "Алгоритмы квантования для полутоновых и цветных изображений" ). Затем выберем число T - порог. После этого построим матрицу B по матрице D по следующему правилу:
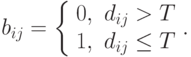
Матрицу B можно рассматривать как задающую ребра в графе, в котором вершинам соответствуют пиксели изображения. Таким образом, связные области графа задают кластеры. Для формирования кластеров можно использовать волновой алгоритм. Положим в каждую вершину графа дополнительное число.
Пусть это число равно 0. Далее выбираем случайную вершину и "поджигаем" ее, т.е. кладем в нее число 1. Затем для каждой вершины, которая соединена ребром с выбранной, кладем 1. После этого то же самое делаем для связных соседей вершин, куда уже положили 1, - им также кладем число 1, и т.д. Таким образом, мы запустили волну. Когда она остановится, это означает, что получены все значения кластера. Далее, следует выбрать случайно ту вершину, которая не попала в кластер, т.е. хранит 0. И запустить для нее волновой алгоритм, например, с числом 2. Проделав такую процедуру несколько раз, получим разбиение на кластеры. В палитру следует положить центры получившихся кластеров.
Приведенный метод хорошо выявляет кластеры точек в общем случае; при этом скорость работы очень высокая. Однако при квантовании фотореалистичных изображений получаются довольно резкие переходы, к тому же явно задать число кластеров невозможно - можно лишь регулировать параметр T. Результаты работы см. на рис. 12.6.
Иерархический метод
Предположим, что в изображении n пикселей и каждый из них образует свой кластер. Свяжем с кластером величину, называемую центром тяжести кластера. Для кластера, состоящего из одного значения, центром тяжести является само значение (в нашем случае, значение атрибута пикселя). Построим матрицу расстояний D между кластерами. В качестве расстояния берется, например, квадрат евклидовой метрики между центрами тяжести кластеров. Затем выберем число T - порог и пару кластеров (i*, j*) так, чтобы (i*, j*) = arg min(i,j) dij (т.е, чтобы di*j* было минимальным в матрице). Объединим кластеры, отвечающие i* и j*, положив центром тяжести нового кластера полусумму центров тяжести объединяемых кластеров. Таким образом, получим n-1 кластеров. Для этих кластеров также построим матрицу расстояний D* и опять найдем пару, имеющую минимальное расстояние между центрами тяжести. Заменим найденную пару одним кластером, вычислив его центр тяжести. Следовательно, получим n - 2 кластеров и т.д.
Мы можем сделать максимум n - 1 итерацию. В таком случае после последней итерации мы получим только один кластер. Чтобы получить K кластеров, нужно сделать n - K итераций.
Данный метод позволяет находить нетривиальные кластеры, однако время его работы очень велико, к тому же затруднена процедура обработки кластеров для большого объема входных данных.
Обобщенный метод K-средних или метод динамических сгущений
Данный метод является развитием идей метода K-средних и борется с его недостатками [27]. В методе K-средних каждому кластеру соответствует определенное значение, его представитель. В качестве представителя кластера выступает его центр, например среднее арифметическое элементов кластера. В идеале, когда перемещения значений из одного кластера в другой отсутствуют, это соответствие - взаимнооднозначное.
Предположим, что представитель кластера - это не одиночное значение, а ядро, обладающее следующими свойствами:
- по представителю можно идентифицировать кластер;
- по кластеру вычисляется представитель.
Пример: представитель - два значения. Данный представитель удовлетворяет первому свойству, т.к. можно корректно определить расстояние от объекта, состоящего из двух значений, до объекта из одного значения. Второе свойство также выполняется, если применить простой алгоритм K-средних с K = 2, т.е. разбить кластер на два, а затем выбрать в качестве представителя исходного кластера центры получившихся двух подкластеров.
Другие примеры представителей: несколько значений, отрезки, разнообразные геометрические фигуры.
Далее обобщенный алгоритм повторяет стандартный алгоритм K-средних: сначала сформировать K кластеров по случайно выбранным ядрам, затем итерировать процесс формирования K новых ядер и пересчета кластеров до тех пор, пока количество перемещений не станет достаточно малым.

Рис. 12.7. Результат работы алгоритма медианного сечения с применением алгоритма рассеивания ошибок Флойда-Стейнберга.
12.6. Заключение
Необходимо отметить, что приведенные выше методы часто применяются вместе с методами распределения ошибок по всему изображению, описанными в предыдущей лекции. Ошибка, возникающая при квантовании, распределяется по изображению. На рис. 12.7 изображен результат работы алгоритма медианного сечения вместе с рассеиванием ошибок Флойда-Стейнберга ( "Алгоритмы повышения количества оттенков (псевдотонирования)" ).