







| Сколько блоков занимает битовая карта блоков, если число блоков в группе равно 128, а размер блока 16? |
Инспектор группы
Вы можете этот курс.
Опубликован: 22.04.2006 | Уровень: специалист | Доступ: свободно
Лекция 27:
Инструмент KXEN
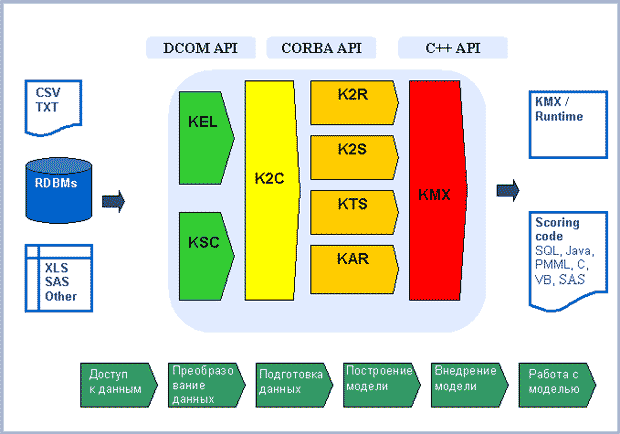
Структура KXEN Analytic Framework Version 3.0
KXEN Analytic Framework по своей сути не является монолитным приложением, а выполняет роль компонента, который встраивается в существующую программную среду. Этот "движок" может быть подключен к DBMS-системам (например, Oracle или MS SQL-Server) через протоколы ODBS.
KXEN Analytic Framework представляет собой набор модулей для проведения описательного и предсказательного анализа. Учитывая специфику задач конкретной организации, конструируется оптимальный вариант программного обеспечения KXEN. Благодаря открытым программным интерфейсам, KXEN легко встраивается в существующие системы организации. Поэтому форма представления результатов анализа, с которой будут работать сотрудники на местах, может определяться пожеланиями Заказчика и особенностями его бизнес-процесса. На рис. 27.2 представлена структура KXEN Analytic Framework Version 3.0.
Рассмотрим ключевые компоненты системы KXEN.
Компонент Агрегирования Событий ( KXEN Event Log - KEL) предназначен для агрегирования событий, произошедших за определенные периоды времени. Применение KEL позволяет соединить транзакционные данные с демографическими данными о клиенте. Компонент используется в случаях, когда "сырые" данные содержат одновременно статическую информацию (например, возраст, пол или профессия индивида) и динамические переменные (например, шаблоны покупок или транзакции по кредитной карте). Данные автоматически агрегируются внутри определенных пользователем интервалов без программирования на SQL или внесения изменений в схему базы данных. Компонент KEL комбинирует и сжимает эти данные для того, чтобы сделать их доступными для других компонентов KXEN.
Преимуществом использования данного компонента является возможность интегрировать дополнительные источники информации "на лету" для того, чтобы улучшить качество модели.
Компонент Кодирования Последовательностей (KXEN Sequence Coder - KSC) позволяет агрегировать события в серии транзакций. Например, поток "кликов" клиента, фиксирующийся на Web-сайте, может трансформироваться в ряды данных для каждой сессии. Каждая колонка отражает конкретный переход с одной страницы на другую. Как и в случае с KEL, новые колонки данных могут добавляться к существующим данным о клиентах и доступны для обработки другими компонентами KXEN.
Преимуществом использования данного компонента является возможность применять незадействованные прежде источники информации для того, чтобы улучшить качество прогнозирующих моделей.
Компонент Согласованного Кодирования (KXEN Consistent Coder - K2C) позволяет автоматически подготовить данные и трансформировать их в формат, подходящий для использования аналитическими приложениями KXEN. Использование K2C позволяет трансформировать номинальные и порядковые переменные, автоматически заполнять отсутствующие значения и выявлять выбросы.
Преимуществом использования данного компонента является возможность автоматизации подготовки данных, которая позволяет освободить время для непосредственно исследований и моделирования.
Компонент Робастной Регрессии (KXEN Robust Regression - K2R) использует подходящий регрессионный алгоритм для того, чтобы построить модели, описывающие существующие зависимости, и сгенерировать прогнозирующие модели. Эти модели могут затем применяться для скоринга, регрессии и классификации. В отличие от традиционных регрессионных алгоритмов, использование K2R позволяет безопасно справляться с большим количеством переменных (более 10 000). Модуль K2R строит индикаторы и графики, которые позволяют легко убедиться в качестве и надежности построенной модели.
Преимуществом использования данного компонента является автоматизация процесса интеллектуального анализа данных. Модели позволяют детализировать индивидуальные вклады переменных.
Компонент Интеллектуальной Сегментации (KXEN Smart Segmenter - K2S) позволяет выявить естественные группы (кластеры) в наборе данных. Модуль оптимизирован для того, чтобы находить кластеры, которые относятся к конкретной поставленной задаче. Он описывает свойства каждой группы и указывает на ее отличия от всей выборки. Как и в случае с другими модулями, этот модуль также строит индикаторы качества и надежности модели.
Преимуществом использования данного компонента является автоматическое выявление групп, значимых для той конкретной задачи, которую необходимо решить.
Машина Опорных Векторов KXEN (Support Vector Machine - KSVM) позволяет производить бинарную классификацию. Использование компонента подходит для решения задач, основанных на наборах данных с небольшим количеством наблюдений и большим количеством переменных. Это делает модуль идеальным для решения задач в областях с очень большим количеством размерностей, таких как медицина и биология.
Преимуществом использования данного компонента является возможность решения задач, которые прежде требовали написания специальных программ, с помощью промышленного программного обеспечения.
Компонент Анализа Временных Рядов (KXEN Time Series - KTS) позволяет прогнозировать значимые шаблоны и тренды во временных рядах. Используйте накопившиеся хронологические данные для того, чтобы спрогнозировать результаты следующих периодов. Модуль KTS выявляет тренды, периодичность и сезонность для того, чтобы получить точные и достоверные прогнозы.
Преимущество: Появляется возможность подстроиться под повторяющиеся шаблоны Вашего бизнеса и предсказывать сокращения поставок до того как они произойдут.
Компонент Экспорта Моделей (KXEN Model Export - KMX) позволяет создавать коды различного типа: SQL, C, VB, SAS, PMML и многих других для встраивания в существующие приложения и бизнес-процессы. Построенная модель в виде кода может быть передана на другую машину для дальнейшего анализа данных в пакетном либо интерактивном режиме.
Преимущество: Использование данного модуля дает возможность производить анализ вновь поступающей информации с помощью модели автономно, вне самой системы моделирования. Это существенно ускоряет внедрение моделей в производственный процесс и не требует создания специальных условий и программ для анализа всей базы данных с помощью модели. Пользователь также может перевести модель на тот язык, который поддерживает его компьютер.
Технология IOLAP
И, в заключение, рассмотрим технологию IOLAP TM от KXEN - интеллектуальную оперативную аналитическую обработку, позволяющую извлечь из данных наиболее релевантную информацию.
Традиционные OLAP-инструменты предоставляют богатую функциональность для детализации, выделения срезов, движения по данным. Однако при значительных объемах информации возникают ограничения в использовании этой функциональности. Как, например, узнать, какие из 200 измерений в кубе имеют существенное отношение к интересующему пользователя вопросу?
Что позволяет IOLAP:
- Структурировать данные таким образом, что в первую очередь отображается наиболее актуальная для пользователя информация.
- Определить и отобразить переменные по степени их значимости по отношению к интересующему вопросу (вклад объясняющих переменных).
- Детализировать иерархию каждой переменной.
- Определить качество и степень достоверности полученных результатов на основе двух индикаторов.
Технология IOLAP ТМ использует алгоритмы, заложенные в аналитических приложениях KXEN, и доступна для работы через Microsoft Excel. Технология IOLAP ТМ легко интегрируется с другими OLAP-средствами и интерфейсами пользователей.