Отладка параллельной программы с использованием Intel Thread Checker
11.2.4.5. Параллельная реализация
Рассмотрим возможный вариант распараллеливания предложенной выше последовательной реализации. Акцент сделаем на корректности реализации, а не на ее производительности, которая не является целью данной лабораторной работы. Приведем лишь одно соображение по поводу производительности. Поскольку метод решения задачи предполагает, что последний уровень дерева обсчитывается отдельно от остальных, начнем наше распараллеливание именно с него. Если подумать, можно обнаружить первый "подводный камень" этой задачи, связанный не с корректностью, но с производительностью разрабатываемой реализации. Легко допустить неточность, посчитав, что распараллеливание на последнем уровне можно опустить. Казалось бы, в чем смысл отдельной работы ради одного уровня? На самом деле смысл есть, поскольку последний уровень содержит наибольшее число узлов, и пренебрегать им при распараллеливании не стоит. Применим для распараллеливания обсчета директиву компилятора #pragma omp parallel for.
Соответствующий фрагмент кода будет выглядеть так:
#pragma omp parallel for
for (j = 0; j < power[l-1]; j++)
RobotTree[j + index[l-1]].expectation =
func(RobotTree[j + index[l-1]].value);Заметим, что переменная j станет локализованной автоматически (согласно стандарту OpenMP), а все остальные по смыслу должны быть общими, поэтому задания дополнительных параметров директивы не требуется.
Перейдем к распараллеливанию основного блока кода, производящего обсчет дерева.
Естественный вариант состоит в разделении всех узлов каждого уровня между потоками. Этого можно добиться по крайней мере двумя способами. Первый состоит в размещении директивы #pragma omp parallel for перед циклом по узлам очередного уровня. В итоге получим:
// Пересчет из конца в начало
// Цикл по уровням
for (level = l - 2; level >= 0;level--)
{
// Цикл по узлам уровня
#pragma omp parallel for private(sum, i, rp)
for (j = 0; j < power[level]; j++)
{
// Для узла level,j подсчитываем expectation
sum = func(RobotTree[ index[level] + j ].value);
// Цикл по потомкам
for (i = 0; i < b; i++)
{
rp = RobotTree[ index[level+1] + b * j + i ];
sum = sum + rp.expectation * rp.probability;
}
RobotTree[ index[level] + j ].expectation = sum;
}Проблема этого варианта состоит в том, что на каждой итерации внешнего цикла происходит "пробуждение" потоков в начале и "засыпание" в конце, что может плохо отразиться на производительности. Поэтому более правильным является вариант, в котором создание параллельной секции происходит один раз перед внешним циклом.
double GetExpectation(void)
{
int i, j, level;
double sum;
TreePart rp;
// Последний уровень
#pragma omp parallel for
for (j = 0; j < power[l-1]; j++)
RobotTree[j + index[l-1]].expectation =
func(RobotTree[j + index[l-1]].value);
#pragma omp parallel
{
// Пересчет из конца в начало
// Цикл по уровням
for (level = l - 2; level >= 0; level--)
{
// Цикл по узлам уровня
#pragma omp for private(sum, i, rp)
for (j = 0; j < power[level]; j++)
{
// Для узла level,j подсчитываем expectation
sum = func(RobotTree[ index[level] + j ].value);
// Цикл по потомкам
for (i = 0; i < b; i++)
{
rp = RobotTree[ index[level+1] + b * j + i ];
sum = sum + rp.expectation * rp.probability;
}
RobotTree[ index[level] + j ].expectation = sum;
}
}
}
return RobotTree[0].expectation;
}11.2.4.6. Анализ параллельной реализации
Собрав проект в соответствии с рекомендациями, изложенными в Описании ITC, запускаем инструмент отладки и обнаруживаем следующие диагностики:
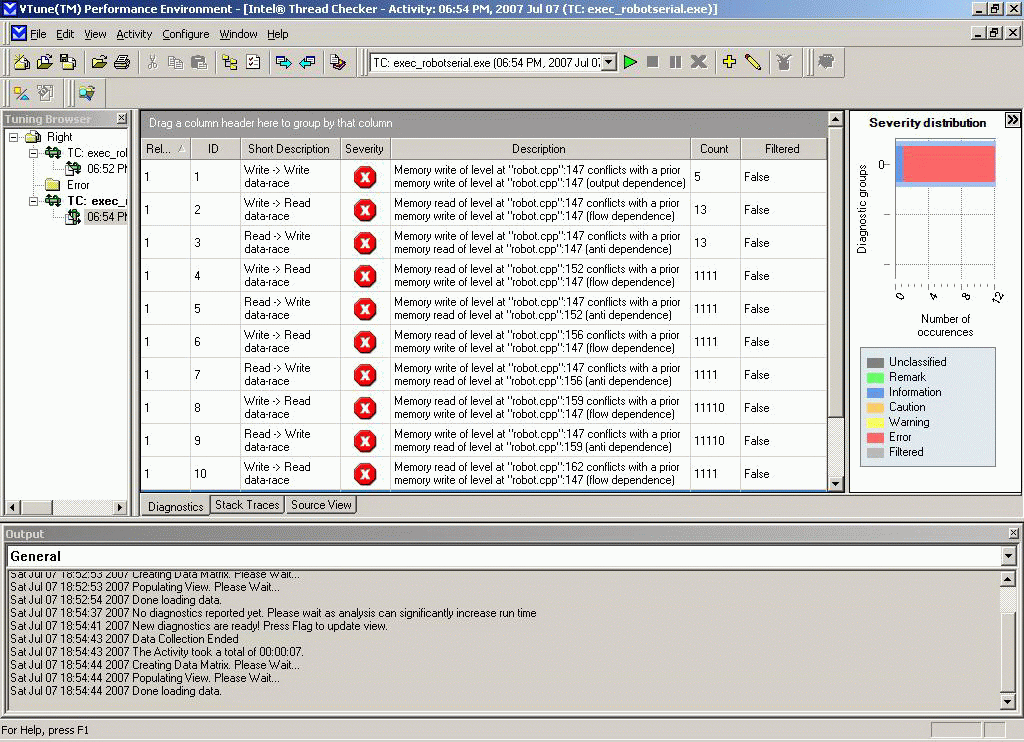
Развернув сообщения об ошибках, мы видим источник проблемы - гонки данных для переменной level. Действительно, предусмотрев локализацию при распараллеливании цикла, мы забыли об этом в директиве #pragma omp parallel. Исправим ошибку и приведем в заключение корректную реализацию.
double GetExpectation(void)
{
int i, j, level;
double sum;
TreePart rp;
// Последний уровень
#pragma omp parallel for
for (j = 0; j < power[l-1]; j++)
RobotTree[j + index[l-1]].expectation =
func(RobotTree[j + index[l-1]].value);
#pragma omp parallel private(level)
{
// Пересчет из конца в начало
// Цикл по уровням
for (level = l - 2; level >= 0; level--)
{
// Цикл по узлам уровня
#pragma omp for private(sum, i, rp)
for (j = 0; j < power[level]; j++)
{
// Для узла level,j подсчитываем expectation
sum = func(RobotTree[ index[level] + j ].value);
// Цикл по потомкам
for (i = 0; i < b; i++)
{
rp = RobotTree[ index[level+1] + b * j + i ];
sum = sum + rp.expectation * rp.probability;
}
RobotTree[ index[level] + j ].expectation = sum;
}
}
}
return RobotTree[0].expectation;
}11.3. Дополнительные задания
- Изучите стандартные примеры, поставляемые вместе с инструментом отладки Intel Thread Checker.
- Изучите постановку задачи умножения матрицы на вектор, последовательные реализации различных алгоритмов, а также предлагаемые пути распараллеливания (см. документ mc_ppr07_forITC.doc). Проанализируйте прилагаемые параллельные реализации, содержащие ошибки (папка Code\MV). Выполните отладку прилагаемых программ, добейтесь их работоспособности.
- Изучите постановку задачи умножения матрицы на матрицу, последовательные реализации различных алгоритмов, а также предлагаемые пути распараллеливания (см. документ mc_ppr08_forITC.doc). Проанализируйте прилагаемые параллельные реализации, содержащие ошибки (папка Code\MM ). Выполните отладку прилагаемых программ, добейтесь их работоспособности.
- Подумайте над задачей об обедающих философах. Рассмотрите другие варианты ее решения. Реализуйте их. Выполните отладку разработанных программ, добейтесь их работоспособности. В качестве одного из средств контроля используйте ITC.