|
поддерживаю выше заданые вопросы
|
Спонсор: Intel
Вы можете этот курс.
Нижегородский государственный университет им. Н.И.Лобачевского
Опубликован: 02.10.2012 | Доступ: свободный | Студентов: 1761 / 202 | Длительность: 17:47:00
Специальности: Программист
Теги:
Лекция 4:
Введение в технологии параллельного программирования (OpenMP)
4.3. Распределение вычислительной нагрузки между потоками (распараллеливание по данным для циклов)
Как уже отмечалось ранее, программный код блока директивы parallel по умолчанию исполняется всеми потоками. Данный способ может быть полезен, когда нужно выполнить одни и те же действия многократно (как в примере 5.1) или когда один и тот же программный код может быть применен для выполнения обработки разных данных. Последний вариант достаточно широко используется при разработке параллельных алгоритмов и программ и обычно именуется распараллеливанием по данным. В рамках данного подхода в OpenMP наряду с обычным повторением в потоках одного и того же программного кода – как в директиве parallel – можно осуществить разделение итеративно-выполняемых действий в циклах для непосредственного указания, над какими данными должны выполняться соответствующие вычисления. Такая возможность является тем более важной, поскольку во многих случаях именно в циклах выполняется основная часть вычислительно-трудоемких вычислений. Для распараллеливания циклов в OpenMP применяется директива for:
#pragma omp for [<параметр> ...] <цикл_for>
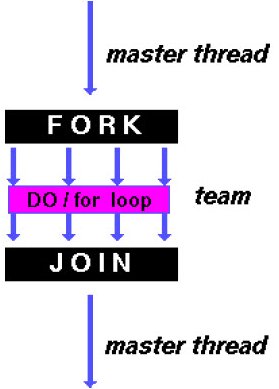
После этой директивы итерации цикла распределяются между потоками и, как результат, могут быть выполнены параллельно (см. рис. 4.4) – понятно, что такое распараллеливание возможно только в случае, когда между итерациями цикла нет информационной зависимости.
Важно отметить, что для распараллеливания цикл for должен иметь некоторый "канонический" тип цикла со счетчиком)2Смысл требования "каноничности" состоит в том, чтобы на момент начала выполнения цикла существовала возможность определения числа итераций цикла:
for (index = first; index < end; increment_expr)
Здесь index должен быть целой переменной; на месте знака "<" в выражении для проверки окончания цикла может находиться любая операция сравнения "<=", ">" или ">=". Операция изменения переменной цикла должна иметь одну из следующих форм:
- index++, ++index,
- index--, --index,
- index+=incr, index-=incr,
- index=index+incr, index=incr+index,
- index=index-incr
И, конечно же, переменные, используемые в заголовке оператора цикла, не должны изменяться в теле цикла.
В качестве примера использования директивы рассмотрим учебную задачу вычисления суммы элементов для каждой строки прямоугольной матрицы:
#include <omp.h>
#define CHUNK 100
#define NMAX 1000
main () {
int i, j, sum;
float a[NMAX][NMAX];
<инициализация данных>
#pragma omp parallel shared(a) private(i,j,sum)
{
#pragma omp for
for (i=0; i < NMAX; i++) {
sum = 0;
for (j=0; j < NMAX; j++)
sum += a[i][j];
printf ("Сумма строки %d равна %f\n",i,sum);
} /* Завершение параллельного фрагмента */
}
4.2.
Пример распараллеливания цикла
В приведенной программе для директивы parallel появились два параметра – их назначение будет описано в следующем разделе, здесь же отметим, что параметры директивы shared и private определяют доступность данных в потоках программы – переменные, описанные как shared, являются общими для потоков; для переменных с описанием private создаются отдельные копии для каждого потока, эти локальные копии могут использоваться в потоках независимо друг от друга.
Следует отметить, что если в блоке директивы parallel нет ничего, кроме директивы for, то обе директивы можно объединить в одну, т. е. пример 5.2 может быть переписан в виде:
#include <omp.h>
#define NMAX 1000
main () {
int i, j, sum;
float a[NMAX][NMAX];
<инициализация данных>
#pragma omp parallel for shared(a) private(i,j,sum)
{
for (i=0; i < NMAX; i++) {
sum = 0;
for (j=0; j < NMAX; j++)
sum += a[i][j];
printf ("Сумма строки %d равна %f\n",i,sum);
} /* Завершение параллельного фрагмента */
}
4.3.
Пример использования объединенной директивы parallel for
Параметрами директивы for являются:
- schedule (type [,chunk])
- ordered
- ordered
- private (list)
- shared (list)
- firstprivate (list)
- lastprivate (list)
- reduction (operator: list)
Последние пять параметров директивы будут рассмотрены в следующем разделе, здесь же приведем описание оставшихся параметров.
Павел Каширин
|
Скачал архив и незнаю как ничать изучать материал. Видео не воспроизводится (скачено очень много кодеков, различных плееров -- никакого эффекта. Максимум видно часть изображения без звука). При старте ReplayMeeting и Start в браузерах google chrome, ie возникает script error с невнятным описанием. В firefox ситуация еще интереснее. Выводится: Meet Now: Кукаева Светлана Александровна. Meeting Start Time: 09.10.2012, 16:58:04 Downloading... Your Web browser is not configured to play Windows Media audio/video files. Make sure the features are enabled and available.
|