Опубликован: 08.07.2008 | Доступ: свободный | Студентов: 1209 / 311 | Оценка: 4.67 / 4.33 | Длительность: 13:24:00
Специальности: Программист, Математик
Теги:
Лекция 5:
Математически эквивалентные преобразования
Аннотация: Математически эквивалентные преобразования,
алгебраические законы на практике не выполняются, эквивалентные
преобразования и устойчивость, эквивалентные преобразования и число
операций, эквивалентные преобразования и параллелизм вычислений,
принцип сдваивания, снова граф алгоритма, граф алгоритма и ошибки
округления, оценка параллелизма алгоритма снизу
Ключевые слова: очередь, законы ассоциативности, эквивалентное преобразование, операции, исключение, умножение, производительность, точность, метод Гаусса, предел, место, алгоритм, вычисление, память, значение, эквивалентные формулы, параллельный компьютер, процессор, сложение, программа, умножение матриц, поиск, параллельные алгоритмы, словосочетание, множества, округленное число, входные данные, ациклический, граф, вершины графа, дуга, аргумент операции, ядро, вывод, унарные операции, выражение, высота, вектор, система линейных алгебраических уравнений, слово
Общее математическое образование в вузах базируется на постулатах, широкое использование которых начинается еще в средней школе. Это, в первую очередь, предположения о выполнении законов ассоциативности, коммутативности и дистрибутивности при реализации операций над числами. Данные законы позволяют построить аппарат математически эквивалентных преобразований символьно-числовых выражений на основе расстановки и раскрытия скобок, приведения и создания подобных членов, перестановки символов и операций и т.п. Аппарат настолько эффективный, что без него не обходится изложение курсов ни по общей, ни по вычислительной математике. Само по себе его применение не вызывает никаких возражений, пока речь идет о проведении преобразований, не связанных с практическим счетом. Но как только дело касается реальных вычислений, формальное применение аппарата математически эквивалентных преобразований становится невозможным в принципе из-за нарушения базисных предположений.
Использование аппарата математически эквивалентных преобразований явно или неявно предполагает, что все операции над символами и числами выполняются точно. Только в этом случае можно считать правомерным выполнение законов ассоциативности, коммутативности и дистрибутивности. И только в этом случае после подстановки вместо символов их конкретных значений будут получены одни и те же значения преобразуемого и преобразованного выражений. Однако заметим, что при реализации операций над числами почти на всех вычислительных системах и компьютерах указанные законы не выполняются. Исключение составляют лишь компьютеры и системы, ориентированные на действия с целыми числами. Конечно, это связано с обязательным по сути дела представлением чисел конечным числом разрядов. Отсюда неизбежно появление ошибок округления как при вводе чисел в систему, так и при реализации арифметических операций. Это и является главной причиной того, что во всех компьютерах, больших или малых, последовательных или параллельных законы ассоциативности, коммутативности и дистрибутивности на всем множестве представимых в компьютерах чисел выполняться не могут. Тем не менее, математически эквивалентные преобразования делаются при разработке алгоритмов и написании программ довольно часто, что нередко приводит к серьезным ошибкам.
Рассмотрим следующий пример. Пусть дана последовательность чисел 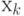 где все равны 1 для
где все равны 1 для 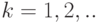 . Построим теперь математически
эквивалентную последовательность чисел
. Построим теперь математически
эквивалентную последовательность чисел 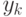 , где
, где 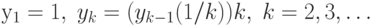 ,
и все вычисляются в соответствии с расставленными
скобками. Очевидно, что при точных вычислениях
,
и все вычисляются в соответствии с расставленными
скобками. Очевидно, что при точных вычислениях 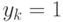 для .
т.е. последовательности чисел
для .
т.е. последовательности чисел 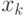 и совпадают. Будем теперь
вычислять последовательность чисел на любом компьютере. Почти все
обратные величины
и совпадают. Будем теперь
вычислять последовательность чисел на любом компьютере. Почти все
обратные величины 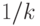 могут быть представлены только бесконечным
числом разрядов. Поэтому в любом компьютере они будут округлены до
некоторого конечноразрядного числа и последующее их умножение на число k не даст точную единицу. Следовательно, вместо чисел реально будут
вычислены некоторые другие числа
могут быть представлены только бесконечным
числом разрядов. Поэтому в любом компьютере они будут округлены до
некоторого конечноразрядного числа и последующее их умножение на число k не даст точную единицу. Следовательно, вместо чисел реально будут
вычислены некоторые другие числа 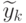 , которые в общем случае не равны
1. Величина
, которые в общем случае не равны
1. Величина 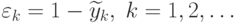 , представляют абсолютную, а в данном
случае и относительную ошибку округления при вычислении выражения
, представляют абсолютную, а в данном
случае и относительную ошибку округления при вычислении выражения 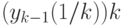 на конкретном компьютере.
на конкретном компьютере.
Заметим, что рассмотренный пример может служить тестом для проверки
того, насколько хорошо реализована операция округления на том или ином
компьютере. Если абсолютные значения чисел остаются ограниченными
при увеличении k, то операцию округления можно считать реализованной
на компьютере достаточно хорошо. В противном случае хорошей ее считать
нельзя. К сожалению, на большинстве компьютеров наблюдается устойчивый
рост абсолютных величин ошибок 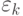 при увеличении чисел k.
при увеличении чисел k.
Объясняется этот факт очень просто. Не только теоретически, но и практически операцию округления всегда можно реализовать так, что при выполнении любой арифметической операции ошибка округления не будет превосходить половины последнего разряда в компьютерном представлении чисел. Но такая идеальная реализация округления приводит к существенному увеличению времени реализации арифметических операций и, следовательно, заметно снижает общую производительность компьютера. Конструктора вычислительной техники редко идут на подобные жертвы. Округление чисел, как правило, реализуется по какой-нибудь упрощенной схеме, что и приводит к значительному накоплению ошибок. Однако уместно задаться таким вопросом: "Если даже на столь простом примере наблюдается устойчивый рост ошибок округления, то какова же будет точность результатов в большой задаче, которая считается подряд много часов или даже дней?".
По-видимому, легко понять, что математически эквивалентные выражения, вычисленные на одном и том же компьютере, почти всегда будут давать разные значения. Как показывает практика, разброс этих значений может быть огромным. Это означает, что проведение математически эквивалентных преобразований изменяет важнейшее вычислительное свойство алгоритма, связанное с устойчивостью. Сам по себе данный факт хорошо известен в научной среде. Но ему можно было бы уделять гораздо больше внимания в среде образовательной, поскольку он играет существенную роль в формировании правильного вычислительного мировоззрения. Значительно меньше известен факт, что проведение математически эквивалентных преобразований изменяет и многие другие важные вычислительные свойства алгоритма.
Рассмотрим, например, задачу отыскания решения системы линейных
алгебраических уравнений с квадратной невырожденной матрицей порядка n. Хорошо известны формулы Крамера,
представляющие решение в явном виде. Алгоритмы, основанные на прямых
вычислениях по этим формулам, требуют для нахождения решения
выполнения порядка 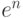 операций. Алгоритмы различных
вариантов метода Гаусса для отыскания решения той же системы требуют
выполнения лишь порядка
операций. Алгоритмы различных
вариантов метода Гаусса для отыскания решения той же системы требуют
выполнения лишь порядка 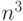 операций. Но ведь они могут
быть получены из формул Крамера путем математически эквивалентных
преобразований! В свою очередь, с помощью тех же преобразований может
быть получен метод Штрассена, который для нахождения решения системы
требует по порядку выполнения всего
операций. Но ведь они могут
быть получены из формул Крамера путем математически эквивалентных
преобразований! В свою очередь, с помощью тех же преобразований может
быть получен метод Штрассена, который для нахождения решения системы
требует по порядку выполнения всего 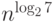 операций. И это не предел!
Следовательно, при проведении математически эквивалентных
преобразований изменяется и другая важная характеристика алгоритма -
число выполняемых операций.
операций. И это не предел!
Следовательно, при проведении математически эквивалентных
преобразований изменяется и другая важная характеристика алгоритма -
число выполняемых операций.
Еще один простой пример. Пусть решается система линейных
алгебраических уравнений с левой треугольной матрицей, имеющей равные
единице диагональные элементы. Предположим, что за основу взят метод
обратной подстановки
[
1
]
. Очевидно,
что из первого уравнения можно определить первое неизвестное, из
второго - второе и т.д. Единственное место, где при такой схеме
имеется возможность существенно изменить алгоритм за счет
математически эквивалентных преобразований - это вычисление суммы
попарных произведений чисел при определении очередного неизвестного.
Казалось бы, совершенно безразлично, какие преобразования делать, так
как во всех традиционных процессах суммирования требуется вьшолнить
одно и то же число операций, используется память одного и того же
размера, да и разброс в достигаемой точности не очень велик. Поэтому с
точки зрения пользователя, решающего задачу на последовательном
компьютере, различия между возможными алгоритмами совсем не
принципиальны и на них можно не обращать внимание. Однако ситуация
меняется радикально, если эту задачу необходимо решать на
вычислительной системе параллельной архитектуры. Легко убедиться в
том, что в рассматриваемом примере при суммировании попарных
произведений подряд справа налево алгоритм оказывается строго
последовательным. Следовательно, у него есть только одна каноническая
параллельная форма и она имеет высоту порядка 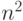 . Если же суммирование
выполняется снова подряд, но слева направо, то можно удостовериться
[
1
]
, что каноническая параллельная форма теперь будет иметь высоту
порядка n. Поэтому при проведении математически эквивалентных
преобразований может меняться даже параллельная структура алгоритма.
Для параллельных вычислений это обстоятельство имеет исключительное
значение.
. Если же суммирование
выполняется снова подряд, но слева направо, то можно удостовериться
[
1
]
, что каноническая параллельная форма теперь будет иметь высоту
порядка n. Поэтому при проведении математически эквивалентных
преобразований может меняться даже параллельная структура алгоритма.
Для параллельных вычислений это обстоятельство имеет исключительное
значение.
Изменение высоты минимальных параллельных форм легко проследить на
такой простой операции как суммирование. Рассмотрим сначала для
наглядности вычисление суммы S восьми чисел 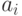 , по двум алгоритмам,
соответствующим таким математически эквивалентным формулам:
, по двум алгоритмам,
соответствующим таким математически эквивалентным формулам:
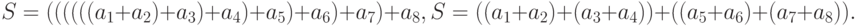
В первом алгоритме никакие операции нельзя выполнять независимо.
Поэтому в нем никакого параллелизма нет и существует только одна
параллельная форма высоты 7. Следовательно, при реализации первого
алгоритма на любом параллельном компьютере на каждом шаге можно
осуществить только 1 суммирование и будет использован только 1
процессор. Всего потребуется 7 шагов. Во втором алгоритме на первом
шаге можно выполнить 4 независимых сложения:  и
и  - На втором шаге можно выполнить 2 независимых сложения:
- На втором шаге можно выполнить 2 независимых сложения:  и
и  .
И, наконец, на третьем шаге за 1 сложение
.
И, наконец, на третьем шаге за 1 сложение 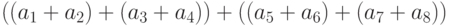 заканчивается вычисление всей
суммы. Это означает, что существует параллельная форма высоты 3 с
максимальной шириной яруса, равной 4. Следовательно, на параллельном
компьютере с 4 процессорами вычисление суммы из 8 чисел можно
выполнить за 3 шага, при этом на первом шаге будут задействованы 4
процессора, на втором 2 и на третьем 1. Отметим, что при вычислениях
по второй схеме на разных шагах используется разное число процессоров.
Это явление говорит о неравномерной загруженности процессоров и
свидетельствует о том, что на данном алгоритме возможности
вычислительной системы используются не полностью.
заканчивается вычисление всей
суммы. Это означает, что существует параллельная форма высоты 3 с
максимальной шириной яруса, равной 4. Следовательно, на параллельном
компьютере с 4 процессорами вычисление суммы из 8 чисел можно
выполнить за 3 шага, при этом на первом шаге будут задействованы 4
процессора, на втором 2 и на третьем 1. Отметим, что при вычислениях
по второй схеме на разных шагах используется разное число процессоров.
Это явление говорит о неравномерной загруженности процессоров и
свидетельствует о том, что на данном алгоритме возможности
вычислительной системы используются не полностью.
При осуществлении суммирования часто требуется знать не только
общий результат, но и все частичные суммы. В первой схеме они
получаются автоматически. Во второй схеме их также можно получить,
причем не увеличивая высоту параллельной формы. Снова рассмотрим
случай 8 слагаемых. На первом шаге выполняем те же 4 независимых
сложения:  и . На втором шаге, кроме сумм и вычисляем также независящие от них 2 выражения
и . На втором шаге, кроме сумм и вычисляем также независящие от них 2 выражения 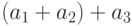 и
и 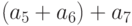 . И, наконец, на третьем шаге помимо суммы всех 8
слагаемых находим независящие от
нее и между собой 3 суммы
. И, наконец, на третьем шаге помимо суммы всех 8
слагаемых находим независящие от
нее и между собой 3 суммы 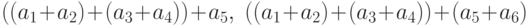 и
и 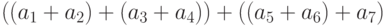 . Все частичные суммы
получены. Обратим внимание, что для их вычисления пришлось выполнить
дополнительно 5 сложений по сравнению с тем случаем, когда находилась
только сумма 8 чисел.
. Все частичные суммы
получены. Обратим внимание, что для их вычисления пришлось выполнить
дополнительно 5 сложений по сравнению с тем случаем, когда находилась
только сумма 8 чисел.
Обе схемы распространяются на случай суммирования n чисел. В первой
схеме для вычисления суммы всегда необходимо выполнить n -1 сложений.
Автоматически находятся все частичные суммы. Минимальная параллельная
форма имеет ту же самую высоту n -1. Во второй схеме вычислить сумму
можно также за n -1 сложений. Но при наличии n /2 процессоров это
удается сделать за 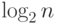 параллельных шагов. Минимальная параллельная
форма имеет такую же высоту . Частичные суммы попутно не
вычисляются. Процессоры загружены очень неравномерно. Однако при
выполнении дополнительно достаточно большого числа сложений порядка
параллельных шагов. Минимальная параллельная
форма имеет такую же высоту . Частичные суммы попутно не
вычисляются. Процессоры загружены очень неравномерно. Однако при
выполнении дополнительно достаточно большого числа сложений порядка 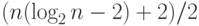 можно на фоне вычисления суммы n чисел одновременно
найти и все частичные суммы. Теперь процессоры на всех шагах будут
загружены полностью. Очевидно, что при реализации первой схемы все
частичные суммы, включая результат полного суммирования, могут быть
размещены на месте входных данных. И совсем не очевидно, что во второй
схеме не только все частичные суммы, а также все промежуточные
результаты тоже могут быть размещены на месте входных данных. Но какой
сложной будет схема замещения одних данных другими и, следовательно,
программа, реализующая вторую схему!
можно на фоне вычисления суммы n чисел одновременно
найти и все частичные суммы. Теперь процессоры на всех шагах будут
загружены полностью. Очевидно, что при реализации первой схемы все
частичные суммы, включая результат полного суммирования, могут быть
размещены на месте входных данных. И совсем не очевидно, что во второй
схеме не только все частичные суммы, а также все промежуточные
результаты тоже могут быть размещены на месте входных данных. Но какой
сложной будет схема замещения одних данных другими и, следовательно,
программа, реализующая вторую схему!