Опубликован: 08.07.2008 | Доступ: свободный | Студентов: 1211 / 311 | Оценка: 4.67 / 4.33 | Длительность: 13:24:00
Специальности: Программист, Математик
Теги:
Лекция 3:
Компьютеры и параллельные формы алгоритмов
Аннотация: Абстрактная модель последовательного компьютера,
влияние последовательных вычислений, развитие параллелизма в
компьютерах, концепция неограниченного параллелизма, граф алгоритма,
необходимость новых сведений о структуре алгоритмов, параллельная
форма алгоритма, абстрактная модель параллельной системы
Ключевые слова: арифметико-логическое устройство, сложение, вычитание, умножение, операции, процессор, память, команда, аргумент операции, ПО, компьютер, алгоритм, программа, Алгол, Си, минимизация, устойчивость, компилятор, очередь, конструирование, параллелизм, язык программирования, производительность, мощность, энергопотребление, внутренний параллелизм, тупик, векторные, параллельный компьютер, интерфейс, объект, входные данные, нумерация, высота, пользователь, операционная система, ресурс, потенциал, языки и системы программирования, автокод, множества, поиск, плата, частичный порядок, дуга графа, дуга, ациклический, граф, значение, вершины графа, параллельные алгоритмы, параллельная вычислительная система, общая память
Несмотря на огромное фактическое разнообразие, все существующие компьютеры и вычислительные системы с точки зрения пользователя условно можно разделить на две большие группы: последовательные и параллельные.
В простейшей интерпретации последовательные компьютеры выглядят следующим образом. Имеются два основных устройства. Одно из них, называемое процессором (центральным процессором, решающим устройством, арифметико-логическим устройством и т.п.), предназначено для выполнения некоторого ограниченного набора простых операций. В набор операций обычно входят сложение, вычитание и умножение чисел, логические операции над отдельными разрядами и их последовательностями, операции над символами и многое другое. Наборы операций, выполняемые процессорами разных компьютеров, могут отличаться как частично, так и полностью. Другое устройство, называемое памятью (запоминающим устройством и т.п.), предназначено для хранения всей информации, необходимой для организации работы процессора. Процессор является активным устройством, т.е. он имеет возможность преобразовывать информацию. Память является пассивным устройством, т.е. она не имеет такой возможности. Процессор и память связаны между собой каналами обмена информацией.
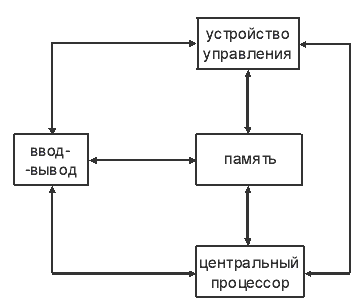
Работа однопроцессорного компьютера заключается в последовательном выполнении отдельных команд. Каждая команда содержит информацию о том, какая операция из заданного набора должна быть выполнена, а также из каких ячеек памяти должны быть взяты аргументы операции и куда должен быть помещен результат. Описание упорядоченной последовательности команд в виде программы находится в памяти. Там же размещаются необходимые для реализации алгоритма начальные данные и результаты промежуточных вычислений. Координирует работу всех узлов компьютера устройство управления. Оно организует последовательную выборку команд из памяти и их расшифровку, передачу из памяти в процессор операндов, а из процессора в память результатов выполнения команд, управляет работой процессора. Ввод начальных данных и выдачу результатов осуществляет устройство ввода-вывода.
По такой схеме устроены все однопроцессорные компьютеры. И это справедливо как для первых в истории электронных вычислительных машин - медленно работающих монстров, занимающих огромные помещения и потребляющих чудовищное количество энергии, так и для современных компактных высокоскоростных персональных компьютеров, размещающихся на письменном столе и потребляющих энергию меньше, чем обычная электрическая лампочка. Конечно, в действительности схемы однопроцессорных компьютеров обрастают большим числом дополнительных деталей. Но всегда процессор является единственным устройством, выполняющим полезную с точки зрения пользователя работу. В этом смысле у любого компьютера все другие устройства по отношению к процессору оказываются обслуживающими, и их работа направлена только на то, чтобы обеспечить наиболее эффективный режим функционирования процессора.
Отсюда следует очень важный вывод: каким бы сложным ни был однопроцессорный компьютер, построенный по классическим канонам, в основе его архитектуры и организации процесса функционирования всегда лежит принцип последовательного выполнения отдельных действий. С точки зрения пользователя отклонения от этого принципа, как правило, не существенны. Именно поэтому такие компьютеры и называются последовательным и.
На каждом конкретном последовательном компьютере время реализации любого алгоритма пропорционально, главным образом, числу выполняемых операций, и почти не зависит от того, как внутренне устроен сам алгоритм. Конечно, какие-то различия во временах реализаций могут появляться. Но они невелики и в обычной практике их можно не принимать во внимание. Это свойство последовательных компьютеров исключительно важно и влечет за собой разнообразные следствия. Пожалуй, самым главным из них является то, что для таких компьютеров оказалось возможным создавать компьютерно-независимые или, как их называют иначе, машинно-независимые языки программирования. По замыслу их создателей любая программа, написанная на любом из таких языков, должна без какой-либо переделки реализовываться на любой последовательной машине. Единственное, что формально требовалось для обеспечения работы программы, - это наличие на машине компилятора с соответствующего языка. Подобные языки стали возникать в большом количестве: Алгол, Кобол, Фортран, Си и др. Многие из них успешно используются до сих пор. Поскольку эти языки ориентированы на последовательные компьютеры, их также стали называть последовательными. Во всех программах, написанных на последовательных языках программирования, порядок выполнения команд всегда является строго последовательным и при заданных входных данных фиксируется однозначно.
Для математиков и разработчиков прикладного программного обеспечения такая ситуация открывала заманчивую перспективу. Не нужно было вникать в устройство вычислительных машин, так как языки программирования по существу мало чем отличались от языка математических описаний. В разработке вычислительных алгоритмов становились очевидными главные целевые функции их качества - минимизация числа выполняемых операций и устойчивость к влиянию ошибок округления. И больше ничего об алгоритмах не надо было знать, поскольку никаких причин для получения каких-либо других знаний и, тем более, знаний о структуре алгоритмов не возникало.
Привлекательность подобной перспективы на долгие годы сделала последовательную организацию вычислений неявным и во многом даже неосознанным фундаментом развития не только численных методов, но и всей вычислительной математики. Заметим, что по своему влиянию на общую направленность исследований в вычислительных делах эта перспектива и в настоящее время во многом остается доминирующей.
На самом деле все, что связано с последовательными компьютерами, развивалось и достаточно сложно, и в какой-то степени драматично. Погоня за производительностью и конкуренция привели к тому, что появилось много разных последовательных машин. Для каждой из них приходилось делать свой компилятор, так или иначе учитывающий особенности конкретной машины. Не в каждом компиляторе удавалось оптимально учитывать эти особенности на всем множестве программ. Поэтому в реальности при переносе программ с одной машины на другую многие программы приходилось модифицировать. Объем изменений мог быть большим или малым и зависел от сложности машин и языков программирования. Проблема переноса программ с одного последовательного компьютера на другой последовательный компьютер становилась со временем все более актуальной и были предприняты значительные усилия на ее решение. В первую очередь, за счет введения различных стандартов на конструирование компьютеров и правила написания программ.
Машины, которые принято называть последовательными, можно называть таковыми лишь с некоторой оговоркой, поскольку в каждый момент времени в них независимо или, другими словами, параллельно выполняется много различных действий. Именно, реализуются какие-то операции, передаются данные от одного устройства к другому, происходит обращение к памяти и т.п. Весь этот параллелизм учитывается при создании компилятора. Степень учета параллелизма компилятором прямым образом сказывается на эффективности работы программ. Однако если параллелизм не виден через язык программирования, то для пользователя он как бы и не существует. Поэтому с точки зрения пользователя можно считать последовательными любые машины, эффективное общение с которыми осуществляется на уровне последовательных языков программирования. Подобная трактовка удобна для пользователей. Но есть в ней и серьезная опасность. Уповая на долговременную перспективу общения с вычислительной техникой на уровне последовательных языков, можно пропустить момент, когда количественные изменения в технике перейдут в качественные и общение с ней при помощи таких языков окажется невозможным. И тогда вроде бы совсем неожиданно, вдруг возникает вопрос о том, что же делать дальше. Именно это и произошло в истории освоения вычислительной техники.
В развитии вычислительной техники многое определяется стремлением повысить производительность и увеличить объем быстрой памяти. Мощности первых компьютеров были очень малы. Поэтому сразу после их появления стали предприниматься попытки объединения нескольких компьютеров в единую систему. Идея была чрезвычайно проста: если мощности одного компьютера нехватает для решения конкретной задачи, то нужно разделить задачу на две части и решать каждую часть на своем компьютере. А чтобы было удобно передавать данные с одного компьютера на другой, необходимо соединить сами компьютеры подходящими по пропускной способности линиями связи. Так появились двухмашинные комплексы. Естественно, на них можно было решать задачи примерно вдвое быстрее. Аналогичным образом строились многомашинные комплексы, объединяющие три, четыре, пять и более отдельных однопроцессорных компьютеров в единую систему. Соответственно повышалась и мощность комплексов. Больших проблем с разделением исходной задачи на несколько независимых подзадач не возникало, поскольку их общее число было невелико.
Несмотря на плодотворность идеи объединения отдельных машин в единый комплекс, долгое время она не получала необходимое развитие. Основные трудности на пути ее практической реализации были связаны с большими размерами первых компьютеров и большими временными потерями в процессах передачи информации между ними. Как следствие, значительного увеличения мощности добиться не удавалось. Но совершенствовались технологии, уменьшались размеры компьютеров, снижалось их энергопотребление. И через некоторое время стало возможно создавать многомашинный комплекс как единую многопроцессорную вычислительную систему с приемлемыми производственными параметрами.
Количество процессоров в системах увеличивалось постепенно. Вообще говоря, в целях достижения максимальной производительности составлять программы для каждого процессора надо было бы индивидуально. Но для пользователя это и не удобно и не привычно. К тому же, необходимо было обеспечить преемственность использования обычных последовательных программ, которых накопилось в мире уже очень много, на системах с несколькими процессорами. Поэтому решение проблемы адаптации последовательных программ к таким системам взяли на себя компиляторы. Однако постепенно внутреннего параллелизма в системах становилось все больше и больше. И, наконец, его стало столь много, что наработанные технологии компилирования программ оказались не в состоянии образовывать оптимальный машинный код. Для его получения в случае многих процессоров компилятору приходится иметь дело с задачей составления оптимального расписания. Решается она перебором и требует, в общем случае, выполнения экспоненциального объема операций по отношению к числу процессоров. Пока число процессоров было невелико, компиляторы как-то справлялись с такой задачей. Но как только их стало очень много, развитие традиционных технологий компилирования зашло в тупик.