Инспектор

Вы можете этот курс.
Опубликован: 22.04.2006 | Уровень: специалист | Доступ: платный
Лекция 5:
Задачи Data Mining. Классификация и кластеризация
Методы, применяемые для решения задач классификации
Для классификации используются различные методы. Основные из них:
- классификация с помощью деревьев решений;
- байесовская (наивная) классификация ;
- классификация при помощи искусственных нейронных сетей;
- классификация методом опорных векторов;
- статистические методы, в частности, линейная регрессия;
- классификация при помощи метода ближайшего соседа;
- классификация CBR-методом;
- классификация при помощи генетических алгоритмов.
Схематическое решение задачи классификации некоторыми методами (при помощи линейной регрессии, деревьев решений и нейронных сетей) приведены на рис. 5.4 - 5.6.
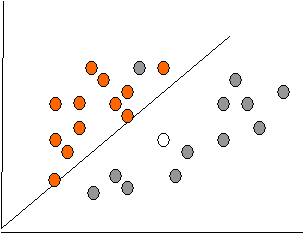
if X > 5 then grey else if Y > 3 then orange else if X > 2 then grey else orange
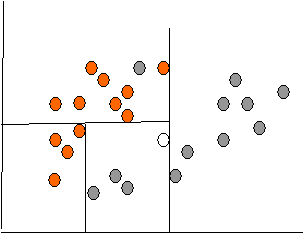
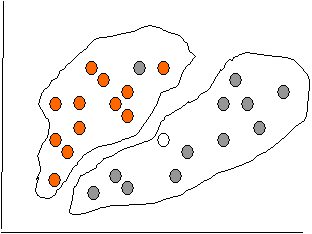
Точность классификации: оценка уровня ошибок
Оценка точности классификации может проводиться при помощи кросс-проверки. Кросс-проверка (Cross-validation) - это процедура оценки точности классификации на данных из тестового множества, которое также называют кросс-проверочным множеством. Точность классификации тестового множества сравнивается с точностью классификации обучающего множества. Если классификация тестового множества дает приблизительно такие же результаты по точности, как и классификация обучающего множества, считается, что данная модель прошла кросс-проверку.
Разделение на обучающее и тестовое множества осуществляется путем деления выборки в определенной пропорции, например обучающее множество - две трети данных и тестовое - одна треть данных. Этот способ следует использовать для выборок с большим количеством примеров. Если же выборка имеет малые объемы, рекомендуется применять специальные методы, при использовании которых обучающая и тестовая выборки могут частично пересекаться.