

|
приветствую создателей курса и благодарю за доступ к информации! понимаю, что это уже никто не исправит, но, возможно, будут следующие версии и было бы неплохо дать расшифровку сокращений имен регистров итд, дабы закрепить понимание их роли в общем процессе. |
Национальный исследовательский ядерный университет «МИФИ»
Опубликован: 03.03.2010 | Доступ: свободный | Студентов: 5429 / 1355 | Оценка: 4.35 / 3.96 | Длительность: 24:14:00
ISBN: 978-5-9963-0267-3
Тема: Аппаратное обеспечение
Специальности: Разработчик аппаратуры
Теги:
Лекция 10:
Структура и особенности архитектуры микропроцессора Pentium 4
Основные черты MMX-технологии
Главной особенностью MMX-технологии является новый принцип обработки информации - обработка по схеме SIMD (SINgle INsTRuction - MultIPle Data: один поток команд - много потоков данных). Этот вид обработки подразумевает, что с помощью одной команды выполняется одна и та же операция сразу над несколькими операндами, например, производится суммирование нескольких пар слагаемых. Такой подход требует поддержки как со стороны системы команд и форматов данных, так и на аппаратном уровне.
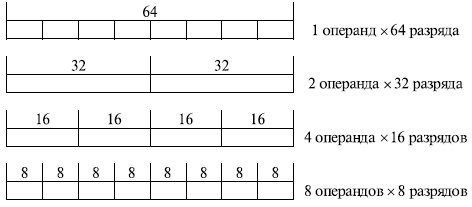
В микропроцессоре Pentium MMX появились 4 новых типа данных (рис. 10.2).
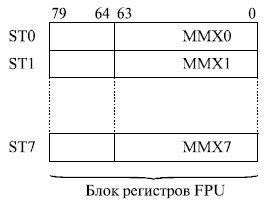
Для хранения этих данных в микропроцессоре были использованы 80-разрядные регистры процессора обработки чисел с плавающей точкой (рис. 10.3).
Многофункциональное использование регистров FPU требовало, чтобы их содержимое сохранялось в памяти компьютера при переходе от
обработки чисел с плавающей запятой к обработке данных MMX и обратно, что несколько ухудшало производительность микропроцессора. Однако это позволило существовавшим в то время операционным системам использовать стандартные механизмы работы с регистрами FPU при сохранении и восстановлении регистров в процессе переключения задач и не потребовало каких-либо доработок ОС.
В систему команд микропроцессора Pentium MMX были включены 57 новых инструкций. Их использование было призвано, во-первых, уменьшить время выполнения мультимедийных приложений, а во-вторых, минимизировать конфликты в конвейере, который становился все более многоступенчатым, что приводило к существенным потерям в производительности из-за конфликтов.
Проиллюстрируем это на примере нескольких команд.
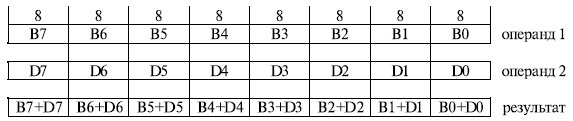
Команда PADDSB "Сложение со знаком с насыщением" (рис. 10.4) выполняет те действия, трудности реализации которых в классической архитектуре IA-32 мы обсуждали выше. Она выполняет сложение одновременно 8 пар однобайтовых операндов. Кроме того, если при выполнении сложения произошло переполнение, то результатом операции будет максимально возможное в этом формате число. Это избавляет программиста от необходимости использования после выполнения каждого сложения команд условных переходов, анализирующих признак переполнения результата, что, в свою очередь, благотворно сказывается на работе конвейера.
Команда PMADDWD "Умножение с накоплением" эффективна при выполнении вычислений, характерных для обработки звуковой и графической информации. Она одновременно перемножает четыре операнда формата "слово" (16 разрядов), попарно складывает результаты умножений двух младших и двух старших байт и получает два 32-разрядных ре зультата (рис. 10.5).
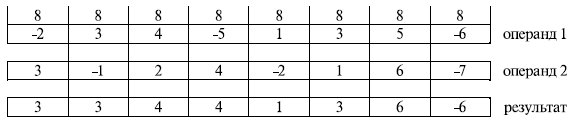
Команда PMAXSB (реализована в блоке SSE микропроцессора Pentium III) выполняет нахождение максимума одновременно для восьми 8-разрядных операндов (рис. 10.6). Она позволяет не только выполнить операцию пакетами по 8 байт, но и избежать ветвлений, а следовательно, и "штрафов" за их неправильное предсказание.
Технология MMX получила свое развитие в микропроцессоре Pentium III с появлением специального блока SSE (STRamINg SIMD Extension - потоковое SIMD-расширение) обработки информации посхеме SIMD. Этот блок содержит отдельный регистровый файл из восьми 128-разрядных регистров (рис. 10.7), что позволяет обрабатывать по схе ме SIMD числа с плавающей запятой (четыре 32-разрядных числа).
Числа с плавающей запятой имеют следующий формат:
- знак: 1 разряд;
- порядок (смещенный): 8 разрядов;
- мантисса: 23 разряда.
Расширено и количество форматов чисел с фиксированной точкой, обрабатываемых по схеме SIMD:
- 16 операндов х 8 разрядов;
- 8 операндов х 16 разрядов;
- 4 операнда х 32 разряда;
- 2 операнда х 64 разряда.
Для обработки чисел новых форматов в систему команд дополнительно введены 70 новых команд.
Блок SSE2, включенный в микропроцессор Pentium 4, реализует 144 новые команды. Из этих 144 инструкций 68 расширяют возможности старых SIMD-инструкций по работе с целыми числами, а 76 являются совершенно новыми. Среди последних - инструкции, позволяющие оперировать со 128-разрядными числами (как целыми, так и вещественными с двойной точностью).
Операции SSE2 позволили существенно повысить эффективность применения микропроцессора при реализации трехмерной графики и современных интернет-приложений, обеспечении сжатия и кодирования аудио- и видеоданных и ряда других применений. В результате производительность процессора Pentium 4 при выполнении таких операций стала вдвое выше, чем Pentium III.
Отметим несколько новых по сравнению с MMX инструкций, вошедших в состав команд SSE/SSE2.
Команда ADDSUBPS выполняет сложение второго и четвертого элементов с одинарной точностью с одновременным вычитанием первого и третьего элементов. Эта инструкция полезна при работе с комплексными числами в случае использования соответствующего типа переменных.
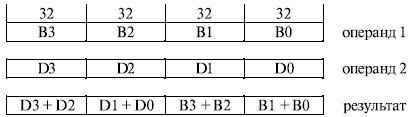
Еще одна команда - HADDPS - осуществляет горизонтальное сложение элементов с одинарной точностью. Первый результат является суммой первого и второго элементов первого (исходного) операнда; второй результат - суммой третьего и четвертого элементов первого операнда; третий результат - суммой первого и второго элементов второго операнда (операнда назначения) и, наконец, четвертый результат - суммой третьего и четвертого элементов второго операнда (рис. 10.8).
Новые возможности в этом направлении обработки информации были обеспечены в технологии SSE3, внедренной в ядре Prescott процессора Pentium 4 добавлением набора из 13 инструкций, и в технологии SSE4 в микропроцессорах семейства INTel Core 2 Duo.
Краткие итоги. В лекции рассмотрены структура и архитектурные особенности микропроцессора INTel Pentium 4, завершающего линейку 32-разрядных микропроцессоров IA-32. Рассмотрены особенности его микроархитектуры, организации новой системной шины FSB, обработки информации в блоке SSE2.
Владислав Салангин
