|
"Теоретически канал с адресацией EUI 64 может соединить порядка запись вида ее можно заменить например на записи вида 264 или 1,8 * 1019
|
Опубликован: 30.07.2013 | Доступ: свободный | Студентов: 1877 / 149 | Длительность: 24:05:00
Тема: Сетевые технологии
Специальности: Архитектор программного обеспечения
Теги:
Лекция 4:
Пакет IPv6
Маршрутный заголовок
Важное следствие сквозной модели, принятой в Internet, состоит в том, что конечные узлы явным образом не участвуют в маршрутизации пакетов. Источник создает пакет IP и отправляет его в сеть, а та уже сама выбирает подходящую трассу, чтобы пакет дошел до адресата. Конечно, инженер понимает, что простирающаяся между конечными узлами сеть состоит из каналов и маршрутизаторов, работающих по вполне определенным правилам, однако узлу-источнику это неинтересно; все, что от него требуется, — это создать пакет и выбрать для него первый шаг. В этой модели источник управляет дальнейшей маршрутизацией пакета только неявно, устанавливая в нем адрес назначения.
В общем случае маршрутизаторы IP могут рассматривать и другие поля заголовка и параметры пакета, например, класс обслуживания или полную длину. Это естественное обобщение простого алгоритма маршрутизации, ответ которого (следующий шаг пакета) зависит только от адреса назначения. Такую обобщенную маршрутизацию часто называют маршрутизация согласно политике (policy routing). Тем не менее, и в этом случае источник пакета влияет на его трассу только неявно.
Тем не менее, еще давным-давно разработчики IPv4 подумали: а вдруг источник иногда бывает осведомлен лучше сети? Например, из-за сбоя или атаки протокол маршрутизации распространил ложные сведения, и маршрутизаторы направляют пакеты не туда, куда надо. Тогда источник мог бы подсказать им верную трассу для своих пакетов, включив эту информацию в заголовок IP. Так появились опции IPv4 LSRR (нестрогая маршрутизация от источника) и SSRR (строгая маршрутизация от источника) [§3.1 RFC 791].
Если обратиться к первоисточнику5 J. Postel, J. Reynolds. Comments on the IP Source Route Option. ISI, 1987. http://www.rfc-editor.org/in-notes/museum/ip-source-route-comments.txt , то можно выделить две задачи маршрутизации от источника в IP. Первая из них состоит в том, чтобы направить пакет по определенной трассе независимо от состояния транзитных узлов. Иными словами, в трассу пакета надо включить желательные транзитные узлы в определенном порядке. Вторая же задача сводится к тому, чтобы исключить из трассы нежелательные маршрутизаторы или сети, направив пакет в обход них. Техническое решение этих задач одинаково и сводится к перечислению транзитных узлов, через которые должен проследовать пакет. Дело в том, что указание транзитному узлу вида: "Ни в коем случае не продвигай пакет через следующий шаг Х", — слабо выполнимо в рамках маршрутизации IP, поскольку у транзитного узла может не быть других вариантов. По этой причине исключение узлов из трассы пакета достигается путем включения в нее других, альтернативных узлов.
Как мы помним, суть работы SRR была довольно простой. Допустим, источник И хотел направить пакет конечному адресату К через транзитные узлы T1, Т2, Т3,…ТN. Тогда он составлял заголовок пакета так:
- помещал адрес Т1 в поле "адрес назначения";
- помещал список адресов {Т2, Т3,…TN, К} в опцию SRR;
-
устанавливал указатель опции SRR так, чтобы тот указывал на первый адрес в списке, то есть Т2.
В результате узел Т1 значился адресатом пакета и поэтому получал его первым. Он поступал с заголовком так:
- определял, на какой адрес в списке указывает указатель опции SRR — Т2;
- копировал адрес Т2¬ в поле "адрес назначения";
- определял выходной интерфейс пакета по его новому адресу назначения;
- записывал локальный адрес выходного интерфейса на место Т2¬ в опции SRR;
- увеличивал указатель на один адрес.
Далее пакет приходил узлу Т2, и тот действовал аналогичным образом… И так далее, пока пакет не добирался наконец до узла К. Разница между строгим и нестрогим режимами состояла в том, мог ли пакет посещать транзитные узлы вне заданного источником списка (в нестрогом мог, а в строгом не мог).
Сегодня мы спросили бы разработчиков этого механизма: а почему сеть должна настолько доверять источнику? Действительно, злонамеренный источник вполне может использовать опции SRR, по меньшей мере, для двух типов атак:
- Обход системы безопасности. Допустим, сеть спроектирована так, чтобы весь трафик проходил через один или несколько узлов-контролеров, например, межсетевых экранов, которые анализируют трафик и применяют к нему ту или иную политику. Но с помощью маршрутизации от источника злоумышленник сможет направить трафик в обход межсетевых экранов, если в физической топологии сети есть такая лазейка.
- Усиление атак типа "отказ в " обслуживании6 P. Biondi, A. Ebalard, "IPv6 Routing Header Security", CanSecWest Security Conference 2007, April 2007. http://www.secdev.org/conf/IPv6_RH_security-csw07.pdf . Положим, злоумышленник хочет подавить маломощный узел А потоком пакетов. Если он включит в каждый пакет опцию LSRR со списком вида "Б, А, Б, А, Б, А…", где Б — сторонний узел, то каждый пакет посетит А не один раз, а несколько! В результате злоумышленнику достаточно создать поток пакетов в N раз меньше, а значит, этот поток может пройти незамеченным через межсетевые экраны, реагирующие на слишком большой трафик между парой узлов.
Пусть читатель сам вычислит максимально достижимый коэффициент усиления атаки  в IPv4.
в IPv4.
Решение: Максимальная длина заголовка IPv4 — 60 байт (4-битное поле, 4-байтная единица длины). Из них 20 байт занимает
обязательная часть, так что на опции остается самое большее 40 байт. Заголовок LSRR занимает 3 байта, но наименьшее допустимое
значение смещения — 4 байта [§3.1 RFC 791], поэтому список адресов занимает до 36 байт, а это означает 9 адресов IPv4. Еще
один адрес — это адрес назначения в основном заголовке. Так что каждый из адресов А и Б может встретиться самое большее 5 раз.
Это и будет искомое значение
Поэтому маршрутизация от источника в глобальной сети приносит больше вреда, чем пользы, и было бы неразумно повторить в IPv6 ошибки IPv4. Из этого затруднения мы выкрутимся вот как: давайте в самом общем виде зададим гибкий формат заголовка, управляющего маршрутизацией пакета IPv6, а всю конкретику оставим на усмотрение дополнительных протоколов. Тогда, в случае чего, нас винить будет не в чем.
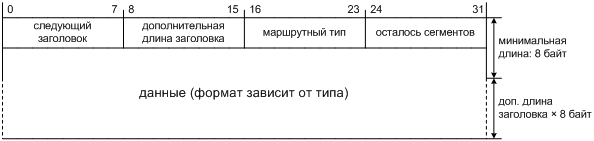
Искомый заголовок расширения IPv6 мы назовем маршрутный заголовок (routing header) [§4.4 RFC 2460]. Ему отвечает значение "следующий заголовок" 43 — разумеется, в предшествующем ему заголовке, а не в нем самом.
Так как длина маршрутной информации заранее неизвестна, маршрутный заголовок будет переменной длины. Значит, помимо обязательного поля "следующий заголовок", маршрутному заголовку потребуется поле длины. По аналогии с заголовками опций из §3.3.2, пусть это поле длиной один байт хранит длину в 8-байтных словах, причем первое слово не учитывается, так как оно всегда присутствует и частично занято фиксированной частью заголовка.
Далее мы поместим поле маршрутного типа, которое и определит, как надо трактовать дальнейшие данные в этом заголовке. Ему будет вполне достаточно одного байта. Конечно же, для общепринятых значений этого поля понадобится реестр7 http://www.iana.org/assignments/ipv6-parameters .
Как быть получателю пакета, если он встретил неизвестный маршрутный тип? Придется ли ему безусловно отбросить этот пакет? Ответить на этот вопрос нам поможет опыт маршрутизации от источника IPv4. (Да, учиться можно и на ошибках!) Когда список транзитных узлов в опции SRR исчерпан и пакет направляется к конечному адресату К, опция SRR отработала и уже не имеет значения для маршрутизации пакета. В этом случае опцию SRR можно игнорировать.
Чтобы перенести эту схему в маршрутный заголовок IPv6, нам придется принять определенную модель его данных. Пусть они состоят из последовательности сегментов, где каждый сегмент может быть, например, адресом транзитного узла. Как обозначить в этой модели, что все сегменты уже обработаны и дальнейшие получатели пакета могут игнорировать маршрутный заголовок, независимо от его типа? Вот одно из возможных решений: хранить в фиксированной части маршрутного заголовка число еще необработанных сегментов. Когда значение этого поля упадет до нуля, получатель пакета надежно определит, что маршрутный заголовок уже отработал свое, даже если получатель не знаком с этим маршрутным типом и не знает, как устроен его сегмент. Если же это поле ненулевое, то пакет с незнакомым типом маршрутного заголовка придется отбросить.
В результате мы приходим к формату маршрутного заголовка, изображенному на рис. 3.13.
Из уже существующих маршрутных типов мы упомянем типы 0 (т.н. RH0 — Routing Header 0) и 2 (RH2). RH0 — это прямой аналог LSRR. Неудивительно, что в конце концов его упразднили ради безопасности [RFC 5095]. Об RH2 см. примечание в конце раздела.
Одно отличие RH0 от LSRR состояло в том, что в текущий сегмент RH0 переносился предыдущий адрес назначения из основного заголовка IPv6, а не адрес выходного интерфейса. Таким образом, в RH0 достаточно было поменять местами адрес назначения и адрес из текущего сегмента, а затем провести декремент счетчика "осталось сегментов". Как следствие, в RH0 происходит простой циклический сдвиг списка адресов, тогда как опция LSRR записывала фактические интерфейсы, в которые продвигался пакет. Точно так же поступала опция SSRR, а нужно это было именно для нее, чтобы потом можно было послать ответный пакет с записанным строгим маршрутом от источника.
При должной политике безопасности на границах опорной сети, запрещающей проникновение сомнительных RH0 извне, внутри такой сети RH0 мог бы стать ценным инструментом для обнаружения скрытых дефектов. Ведь с его помощью можно было бы из одной точки проверять разные пути сквозь сеть, включая неактивные в данный момент, запасные. Корреляция результатов подобных проверок вдоль множества путей позволяет довольно точно определить, где локализован дефект8 N. Guilbaud. Google Backbone monitoring. Localizing packet loss in a large complex network. AusNOG . Так что приходится признать, что RH0 был упразднен не по причине его бесполезности или неизлечимых проблем, а из-за низкой культуры сетевой безопасности, по-прежнему довлеющей над Internet и делающей данный инструмент опасным для его же владельца.
Существование маршрутного заголовка IPv6 заставляет нас пересмотреть такое понятие, как адресат пакета. До сих пор мы полагали, что у пакета ровно один адресат, хотя он может быть индивидуальным узлом или группой. Теперь же нам придется различать два типа адресатов. Если в пакете вообще нет маршрутного заголовка или же он есть, но его поле "осталось сегментов" равно нулю, то в основном заголовке IPv6 записан конечный адресат пакета. Это узел, который поглотит пакет и обработает его полезную нагрузку. Если же в маршрутном заголовке все еще есть активные сегменты, то в основном заголовке IPv6 значится текущий адресат пакета. Этот узел примет пакет, только чтобы сменить в нем адрес назначения и передать дальше; он будет транзитным на пути пакета. При этом конечный адрес назначения пакета скрыт в сегменте маршрутного заголовка.
Вообще говоря, ни один из адресов назначения в пакете с маршрутным заголовком не должен быть групповым. Это следует из соображений безопасности.
Нужны ли дополнительные правила, если у адреса назначения в маршрутном заголовке область действия не глобальная? На самом деле, нет, достаточно уже знакомого нам принципа изоляции зон из §2.4. Однако, строго говоря, этот принцип должен выполняться — а значит, и проверяться — для всех адресов назначения одновременно. В противном случае возможна атака засылкой пакета в удаленную зону. Например, если текущий адресат пакета глобальный, а конечный адресат внутриканальный, то произойдет засылка внутриканального пакета в канал, не подключенный непосредственно к источнику пакета.
Нормативный документ [§9 RFC 4007] требует, чтобы следующий адрес назначения из маршрутного заголовка имел область не меньшей величины, чем у текущего адреса назначения в основном заголовке IPv6. Пока принцип изоляции зон выполняется и все интерфейсы назначения пакета находятся в зоне его адреса источника, это требование избыточно. К примеру, вполне возможна "эстафета" по адресам, область которых сужается, если все они назначены интерфейсам в тот же канал, где находится интерфейс-источник.
Маршрутизация от источника обрела новую жизнь в MPLS-TE, где вполне можно задать трассу LSP по узлам, перечислив их адреса в ERO. Конечно, этот механизм выгодно отличается от RH0 в IPv6 в плане безопасности, так как пограничный узел (LER), устанавливающий LSP, — заведомо доверенный, в отличие от абстрактного источника IPv6. Однако на поверку MPLS не столь уж независим от IP: не имея собственной адресации, он опирается в этом на традиционный протокол сетевого уровня, и обычно это IP. Поэтому, если узлам MPLS назначены зонные адреса IPv6, то ERO подчиняется все тому же принципу изоляции зон! А именно входной LER должен иметь возможность адресовать каждый узел по трассе LSP, иначе ERO будет лишен смысла. В частности, именно поэтому нельзя проложить трассу LSP через несколько каналов, используя только внутриканальные адреса: для составления ERO потребуются адреса большей области, по крайней мере, начиная со второго узла вдоль трассы. Это в высшей степени любопытно, что наши разработки для маршрутизации от источника IPv6 также применимы к MPLS!
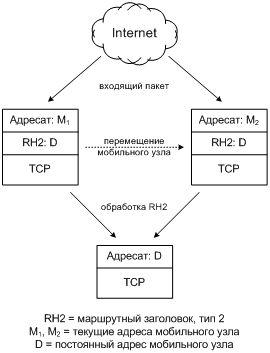
Как мы знаем, узел может адресовать пакеты IP самому себе. Точно так же, текущий и конечный адреса назначения могут принадлежать одному и тому же узлу. Но зачем это нужно? Например, чтобы текущий адрес назначения обладал свойствами локатора, а конечный — идентификатора. Это полезно, если узел мобильный и перемещается по Internet. Текущий адрес мобильного узла M в каждый момент времени доступен обычным порядком, с помощью маршрутизации, и может меняться, когда узел меняет свое местоположение. В то же время, его постоянный адрес D, с которым работают вышестоящие протоколы, доступен только посредством маршрутного заголовка. Тогда перемещения узла будут прозрачны для протоколов уровня выше IP, как показано на рис. 3.14. Очевидно, что такой маршрутный заголовок может содержать ровно один сегмент, причем адрес в нем обязан совпасть с постоянным адресом текущего адресата D. В противном случае налицо сбой или нарушение безопасности. Даная разновидность маршрутного заголовка получила маршрутный код 2 и потому известна как RH2. Подробнее с ней можно познакомиться в RFC 3775, посвященном мобильности узлов IPv6.
Сергей Субботин
 "
"
Павел Афиногенов
|
Курс IPv6, в тексте имеются ссылки на параграфы. Разбиения курса на параграфы нет. |