Проектирование архитектуры кластерной системы
В настоящее время большинство серверных материнских плат имеют интегрированный рейд-контроллер, но к нему не всегда можно подключить более 2-4 дисков. На рынке подобные решения представлены исключительно широко: от внутренних плат рейд-контроллеров, до аппаратных файл- серверов.
Если предполагается использовать RAID-1, -5 или -6, то полезно подумать о запасных (spare) дисках. Они не используются до тех пор, пока основные диски работают нормально. Как только один из жёстких дисков выходит из строя, вместо него подключается запасной. На него записывается вся необходимая информация, которая восстанавливается с работающих носителей за счёт изначальной избыточности хранения (поэтому такие диски не столь полезны в RAID-0), и работа RAID-массива продолжается в нормальном режиме. На один RAID-массив стоит выделить хотя бы один такой диск. Убедитесь, что RAID-контроллер поддерживает работу с запасными дисками и умеет включать их в работу автоматически, без остановки работы массива.
Сетевая инфраструктура в современных кластерных системах представлена тремя вариантами сетей: коммуникационная, транспортная и сервисная. Во многих проектах все три сети присутствуют одновременно.
Коммуникационная сеть - это тот компонент, который во многом определит эффективность работы программ на будущем кластере, поскольку именно с помощью этой сети процессы параллельных программ обмениваются данными между собой. Какими характеристиками выражается производительность коммуникационных сетей в кластерных системах? Для работы параллельных приложений в наибольшей степени важны две характеристики: латентность и пропускная способность сети. Латентность - это время, необходимое для передачи сообщения нулевой длины от одного процесса параллельной программы другому. Пропускная способность сети определяет собственно скорость передачи информации по каналам связи. Если в программе много маленьких сообщений, то на эффективность ее выполнения сильно скажется латентность. Если сообщения передаются большими порциями, то важна высокая пропускная способность каналов связи. Заметим, что из-за латентности максимальная скорость передачи по сети не может быть достигнута на сообщениях с небольшой длиной, а насколько быстро реальные показатели приближаются к заявленным характеристикам - это будет определяться и типом сети, и набором оборудования от конкретного производителя. На практике не столько важны указанные производителем пиковые характеристики коммуникационной аппаратуры, сколько реальные показатели, достигаемые на уровне приложений пользователей, в частности, на уровне MPI-программ или прикладных пакетов.
Выбор коммуникационной сети полностью определяется свойствами решаемых задач (выполняемых программ) и целями создания кластерной системы. Если обменов между параллельными процессами приложения мало, то достаточно использовать какой-либо вариант Ethernet. В зависимости от объемов пересылок это 100 Мбит/с или 1 Гбит/с. Серьезным недостатком сети Ethernet является высокая латентность, составляющая около 130-150 мкс на пакет. Некоторые современные коммутаторы позволяют снизить этот показатель до 50-60 мкс, однако для многих вычислительных задач это все равно не решает проблемы.
В данный момент на рынке доступны несколько стандартов сетевого оборудования, дающего скорости более 1 Гбит/с, и со значительно более низкой латентностью. Рассмотрим наиболее распространенные и доступные варианты.
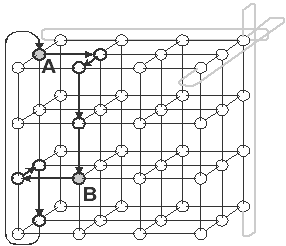
Сетевая технология SCI. Скорость передачи данных около 700 Мбайт/с (5,6 Гбит/с), аппаратная латентность на уровне 0,2 мкс. На МРI-приложениях скорость передачи данных достигает значений около 350 Мбайт/с, а латентность - 1,4 мкс. Особенностью данной сетевой технологии является то, что она не требует коммутатора. Все сетевые адаптеры соединяются в кольцо либо тор (поддерживаются двумерные и трехмерные топологии). На рис. 3.4 показан пример объединения машин кластера с топологией трехмерного тора. Два кластера суперкомпьютерного комплекса НИВЦ МГУ использовали технологию SCI, объединяя узлы в соответствии со структурой двумерного тора. Кластер СКИФ-К500, установленный в ОИПИ НАНБ, использует технологию SCI с объединением 64 узлов в трехмерный тор.
С одной стороны такая архитектура кажется выгодной, так как не нужно приобретать дополнительного оборудования, только сетевые адаптеры. При добавлении новых узлов также не надо заботиться о покупке нового коммутатора. С другой стороны, опыт показывает, что эта технология весьма трудоемка при первоначальной настройке. Более того, находить ошибки или сбои в коммутации такой сети крайне сложно. Средств для ее диагностики существует очень мало. Но самым неудобным является то, что выход из строя одного вычислительного узла означает отключение двух (для двумерного тора) или трех (для трехмерного) колец связи. Сбой двух узлов в двумерном торе приведет к отключению еще двух других узлов, лежащих на пересечении отключенных колец. Для трехмерного тора аналогичное отключение произойдет при сбое трех узлов.
Сетевая технология Myrinet-2000/Myri-10G. Скорость передачи данных - 2 Гбит/с и 10 Гбит/с соответственно. Для МРI-приложений достигается скорость 247 Мбайт/с и 1,2 Гбайт/с, латентность - 2,6 мкс и 2 мкс. Данная технология использует оптоволоконные соединения. При построении сети используются коммутаторы, которые можно соединять между собой. Драйверы и программное обеспечение распространяются бесплатно. Стандарт Myrinet существует довольно давно, поэтому широко поддерживается. Технология Myrinet в течение уже многих лет активно используется в Межведомственном суперкомпьютерном центре РАН для построения нескольких поколений суперкомпьютерных кластерных систем.
Сетевая технология InfiniBand. Скорость передачи данных до 10 Гбит/с, латентность - менее 1 мкс. На MPI-приложениях скорость передачи данных в дуплексном режиме достигает 2,5 Гбайт/с, латентность - 1,3-1,7 мкс. Реальная скорость передачи в настоящее время ограничивается скоростью шин PCI-X и PCI-Express. В случае PCI-X адаптеров скорость составит не более 1 Гбайт/с. Не так давно анонсировано сетевое оборудование, построенное по этой же технологии, со скоростью передачи данных до 30 Гбит/с.
Технология InfiniBand разработана альянсом ведущих мировых разработчиков: Intel, IBM, Cisco, Sun и рядом других. В настоящее время на компьютерном рынке представлено множество брендов, поставляющих это оборудование, например, только что упоминавшаяся компания Cisco, Qlogic или Mellanox.
Данная технология одна из самых молодых среди аналогов, но и одна из самых быстро развивающихся. При построении сети используются коммутаторы, которые можно объединять между собой. Аппаратно поддерживается маршрутизация пакетов, при этом дублирующиеся маршруты используются для балансировки нагрузки.
При соединении нескольких коммутаторов часто используется топология "Fat-Tree". В этом случае коммутаторы соединяются несколькими каналами параллельно, что увеличивает скорость канала между ними. Базовая поддержка InfiniBand уже есть в последних ядрах Linux. Существуют библиотеки MPI и программное обеспечение для работы с InfiniBand, распространяемые бесплатно.
В настоящее время коммуникационные технологии развиваются очень быстро. Недавно появились и уже сегодня доступны на рынке технологии Quadrics и 10 Gbit Ethernet, представлены опытные образцы технологии 100 Gbit Ethernet.
Кроме коммуникационной сети, по которой будут обмениваться информацией параллельные приложения, рекомендуем отдельно поставить транспортную сеть (иногда ее называют управляющей сетью). По ней происходит передача данных сетевой файловой системы и может осуществляться управление вычислительными узлами.
Разделение коммуникационной и транспортной сетей необходимо для того, чтобы вспомогательный трафик не мешал работе параллельных приложений. Даже если в качестве коммуникационной сети используется Ethernet, поставьте второй коммутатор и настройте на нем независимую транспортную сеть. Затраты небольшие, а в трудных ситуациях это поможет не только спасти данные, но и значительно облегчить работу администратору и избежать долгих часов простоя системы.
Еще одна сеть, о которой нужно обязательно упомянуть, это сервисная сеть. Эта сеть используется исключительно для обслуживания вычислительных узлов. Оконечным оборудованием для этой сети должен быть, строго говоря, даже не вычислительный узел, а устройство, способное его контролировать. На многих современных серверных платформах такие устройства устанавливаются изначально. Эти устройства доступны и отдельно, например, платы Hewlett-Packard Lights-Out или платы ServNet, разработанные в Институте программных систем РАН. Все они предоставляют различный уровень сервиса от минимальной возможности удаленно перезагрузить узел, включить или выключить питание, до получения графической консоли.
Крайне важной может оказаться информация с системной консоли при диагностике сбоев: узел завис, и получить доступ к консоли штатными средствами невозможно. Большинство имеющихся на рынке устройств доступ к системной консоли дают. Например, плата ServNet позволяет получить не только доступ к консоли через стандартный СОМ-порт, но также управлять питанием узла. Такой функциональности вполне достаточно для решения большинства задач по удаленному обслуживанию кластера.
Получить дополнительную информацию об упомянутых технологиях можно на сайте http://skif.pereslavl.ru/ (поиском слова ServNet) и поиском по ключевым словам "Lights-Out 100 Remote Management Card" на сайте http://www.hp.com.
Наличие сервисной сети сильно упрощает обслуживание кластера. Администратору не надо идти в другое помещение для того, чтобы перезагрузить зависший узел, можно быстро выяснить причину зависания, а в некоторых случаях даже переустановить ОС прямо со своего рабочего места.
Очень важный момент, про который забывают или на котором часто возникает желание сэкономить, - это обеспечение качественного электропитания. От этого будет зависеть и долговечность работы кластера, и степень его доступности, и работоспособность критических приложений. Включить в конфигурацию источник бесперебойного питания стоит хотя бы для того, чтобы элементарно защитить вычислительные узлы. Корректное выключение кластера в случае аварийного выключения питания поможет спасти данные долгих расчетов, а очень часто и значительное время, необходимое на восстановление работоспособности кластера.
На практике чаще всего возникают кратковременные скачки напряжения, с чем любой UPS прекрасно справится. Более серьезный вариант предполагает, что UPS сможет обеспечить работу кластера в течение 5-10 минут. Рассчитать мощность UPS можно исходя из мощности подключенного к нему оборудования. Для работоспособности приложений во время непредвиденных скачков по питанию не забудьте подключить к UPS не только вычислительные узлы, но и все сетевые коммутаторы.
Обязательно завершите проектирование составлением подробной схемы кластерной системы, показывающей архитектуру комплекса, его составные части, детали компоновки, особенности размещения, структуру коммуникаций. Не забывайте в будущем модифицировать схему сразу после модернизации кластера, поскольку даже очевидные действия со временем забываются, и много времени будет уходить на восстановление и правильное описание текущей конфигурации.
И еще раз повторим вопрос, поставленный в конце предыдущего раздела. Будет ли кластер расширяться или как-то модифицироваться в будущем? Финансирование проекта часто появляется порциями и возникает большое желание сначала купить часть системы, а потом ее нарастить еще каким-то числом узлов. К такому сценарию развития кластерного проекта подталкивает и тот факт, что архитектуры кластерных систем хорошо масштабируются, поэтому принципиальных препятствий для расширения нет.
Если выбирается вариант последовательного развития кластерной системы, то, как правило, выбирают два пути. Первый предполагает добавления какого-то числа новых вычислительных узлов в существующую систему. Основная проблема здесь одна: если возможность для расширения появилась через полгода-год после создания первой версии системы, то возникает вопрос о целесообразности покупки уже устаревшего оборудования. Приобретать такие же узлы уже не хочется, так как на рынке по схожей же цене есть более привлекательные модели. Но если купить современные варианты узлов, то кластер перестанет быть однородным, и возникнут очевидные проблемы с его использованием. Второй путь развития - это полная замена каких-либо компонентов системы на новые аналоги: более мощные процессоры, больший объем памяти, новые диски, новые материнские платы с увеличенной частотой системной шины и т.п. И по такому пути вполне можно двигаться, но постарайтесь сразу ответить на сакраментальный вопрос: что делать со старыми комплектующими?
Любое оборудование, даже фирменное и самое дорогое, ломается. Не пренебрегайте изучением гарантийных обязательств производителя, а также его технической поддержкой и сервисным обслуживанием. Эти позиции можно и нужно включать в проект. Гарантия производителя позволит заменить сбойную деталь или целый узел в случае брака, но на это может уйти несколько дней или даже недель. Техническая поддержка позволит избавиться от необходимости искать самим сбойный компонент и перепоручить эту обязанность профессионалам. Особенно удобно, если предусмотрена поддержка "on-site", когда специалист выезжает прямо на место установки кластера. Сервисное обслуживание позволит проводить не только обмен сбойных компонент, но и ремонт узлов.
Наличие гарантии, безусловно, дает уверенность в том, что сбойный компонент будет заменен. Однако оно не дает уверенности в том, что он будет заменен быстро. Если приложению необходимы все процессоры, а один из них вышел из строя, то дело встанет. Придется ждать замены, которая займет от нескольких дней, до нескольких недель в зависимости от гарантийных обязательств поставщика и производителя оборудования.
Чтобы избежать подобной неопределенности хорошим решением станет резервный узел. Его можно заранее сконфигурировать, но не включать в общее счетное поле. При выходе одного из узлов из строя его можно заменить резервным на время ремонта. Это особенно важно для тех кластерных систем, в которых узлы расположены по некоторой жестко заданной структуре, а выход из строя одного узла может нарушить структуру целого сегмента (например, SCI-кластеры с топологией двумерного или трехмерного тора).
Другое решение - это резервные запчасти. Вместо целого узла можно приобрести в резерв только наиболее часто ломающиеся детали, в частности, жесткие диски, вентиляторы для охлаждения, модули памяти, блоки питания, а также запасные коммуникационные карты.
По какому пути обеспечения резерва пойти в каждом конкретном проекте: резервные узлы, компоненты или же вообще отказаться от резерва, - это предстоит решить руководству каждого кластерного проекта самостоятельно. Решение определяется и бюджетом, и стоящими задачами, и требуемой степенью доступности кластерной системы. Что- либо сказать априори одинаково хорошо подходящее для любого случая здесь практически невозможно.
Всегда хочется как-то проверить принятые решения и сравнить с чем- то уже работающим, поэтому в "Приложение 1. Примеры существующих кластерных проектов" приведено несколько примеров программно-аппаратных конфигураций реально существующих кластерных систем. Множество других вариантов можно найти на страницах информационно-аналитического центра Parallel.ru, а также на сайте http://www.supercomputers.ru списка Тор50 самых мощных компьютеров СНГ - большинство из них являются кластерами.