
|
Здравствуйте! 4 июня я записалась на курс Прикладная статистика. Заплатила за получение сертификата. Изучала лекции, прошла Тест 1. Сегодня вижу, что я вне курса! Почему так произошло? |
Инспектор
Вы можете этот курс.
Опубликован: 09.11.2009 | Уровень: для всех | Доступ: платный
Лекция 11:
Статистика нечисловых данных
11.2. Теория случайных толерантностей
В прикладных исследованиях обычно используют три конкретных вида бинарных отношений - ранжировки, разбиения и толерантности. Статистические теории ранжировок [ [ 11.10 ] ] и разбиений [ [ 11.16 ] ] достаточно сложны с математической точки зрения. Поэтому продвинуться удается не очень далеко. Теория случайных ранжировок, в частности, изучает в основном равномерные распределения на множестве ранжировок. Теория случайных толерантностей позволяет рассмотреть более общие ситуации. Это объясняется, грубо говоря, тем, что для теории толерантностей оказываются полезными суммы некоторых независимых случайных величин, а для теории ранжировок и разбиений аналогичные случайные величины зависимы. Теория случайных толерантностей является частным случаем теории люсианов, рассматриваемой в 11.3. Здесь приводим результаты, специфичные именно для толерантностей.
Пусть 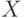 - конечное множество из
- конечное множество из 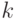 элементов. Толерантность
элементов. Толерантность  на множестве , как и любое бинарное отношение, однозначно описывается матрицей
на множестве , как и любое бинарное отношение, однозначно описывается матрицей  , где
, где 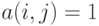 , если элементы с номерами
, если элементы с номерами  и
и 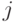 связаны отношением толерантности, и
связаны отношением толерантности, и 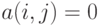 в противном случае. Поскольку толерантность - это рефлексивное и симметричное бинарное отношение, то достаточно рассматривать часть матрицы, лежащую над главной диагональю:
в противном случае. Поскольку толерантность - это рефлексивное и симметричное бинарное отношение, то достаточно рассматривать часть матрицы, лежащую над главной диагональю:  . Между наборами
. Между наборами  из 0 и 1 и толерантностями на имеется взаимнооднозначное соответствие.
из 0 и 1 и толерантностями на имеется взаимнооднозначное соответствие.
Пусть 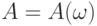 - случайная толерантность, равномерно распределенная на множестве всех толерантностей на . Легко видеть, что в этом случае
- случайная толерантность, равномерно распределенная на множестве всех толерантностей на . Легко видеть, что в этом случае 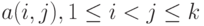 , - независимые случайные величины, принимающие значения 0 и 1 с вероятностями 0,5. Этот факт, несмотря на свою математическую тривиальность, является решающим для построения теории случайных толерантностей. Для аналогичных постановок в теории ранжировок и разбиений величины
, - независимые случайные величины, принимающие значения 0 и 1 с вероятностями 0,5. Этот факт, несмотря на свою математическую тривиальность, является решающим для построения теории случайных толерантностей. Для аналогичных постановок в теории ранжировок и разбиений величины 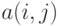 оказываются зависимыми.
оказываются зависимыми.
Следовательно, случайная величина
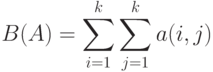
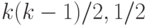 и асимптотически нормальна при
и асимптотически нормальна при 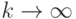 .
.Проверка гипотез о согласованности. Рассмотрим  независимых толерантностей
независимых толерантностей 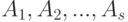 , равномерно распределенных на множестве всех толерантностей на . Рассмотрим вектор
, равномерно распределенных на множестве всех толерантностей на . Рассмотрим вектор
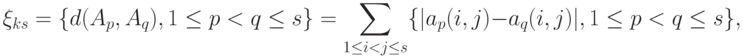 |
( 1) |
 - расстояние между толерантностями
- расстояние между толерантностями 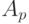 и
и 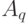 , аксиоматически введенное в
"Различные виды статистических данных"
. В (1) предполагается, что пары
, аксиоматически введенное в
"Различные виды статистических данных"
. В (1) предполагается, что пары 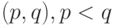 , располагаются в раз и навсегда установленном порядке, для определенности - в лексиграфическом (т.е. пары упорядочиваются в соответствии со значением
, располагаются в раз и навсегда установленном порядке, для определенности - в лексиграфическом (т.е. пары упорядочиваются в соответствии со значением  , а при одинаковых - по значению
, а при одинаковых - по значению 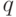 ).
).Вектор 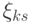 является суммой
является суммой  независимых одинаково распределенных случайных векторов, а потому асимптотически нормален при . Координаты этого вектора независимы, поскольку, как нетрудно видеть, координаты каждого слагаемого независимы (это свойство не сохраняется при отклонении от равномерности распределения). Распределения случайных величин
независимых одинаково распределенных случайных векторов, а потому асимптотически нормален при . Координаты этого вектора независимы, поскольку, как нетрудно видеть, координаты каждого слагаемого независимы (это свойство не сохраняется при отклонении от равномерности распределения). Распределения случайных величин 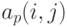 и
и 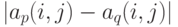 совпадают, поэтому распределения
совпадают, поэтому распределения 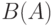 и также совпадают.
и также совпадают.
В силу многомерной центральной предельной теоремы ( "Теоретическая база прикладной статистики" ) распределение вектора
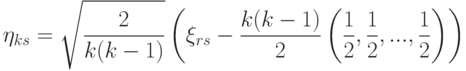 к распределению многомерного нормального вектора
к распределению многомерного нормального вектора 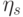 , ковариационная матрица которого совпадает с ковариационной матрицей вектора
, ковариационная матрица которого совпадает с ковариационной матрицей вектора  , а математическое ожидание равно 0. Таким образом, координаты случайного вектора независимы и имеют стандартное нормальное распределение с математическим ожиданием 0 и дисперсией 1. В соответствии с теоремами о наследовании сходимости (
"Теоретическая база прикладной статистики"
) распределение
, а математическое ожидание равно 0. Таким образом, координаты случайного вектора независимы и имеют стандартное нормальное распределение с математическим ожиданием 0 и дисперсией 1. В соответствии с теоремами о наследовании сходимости (
"Теоретическая база прикладной статистики"
) распределение 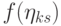 сходится при к распределению
сходится при к распределению 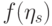 для достаточно широкого класса функций
для достаточно широкого класса функций  , в частности, для всех непрерывных функций. В качестве примеров рассмотрим статистики
, в частности, для всех непрерывных функций. В качестве примеров рассмотрим статистики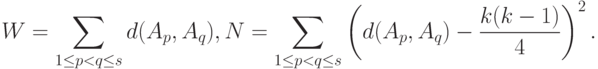
При распределения случайных величин
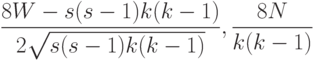
 степенями свободы. Статистики
степенями свободы. Статистики 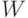 и
и 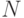 могут быть использованы для проверки гипотезы о равномерности распределения толерантностей.
могут быть использованы для проверки гипотезы о равномерности распределения толерантностей.Как известно, в теории ранговой корреляции [
[
11.10
]
], т.е. в теории случайных ранжировок, в качестве единой выборочной меры связи нескольких признаков используется коэффициент согласованности 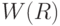 , называемый также коэффициентом конкордации [
[
2.1
]
, табл.6.10]. Его распределение затабулировано в предположении равномерности распределения на пространстве ранжировок (без связей). Непосредственным аналогом в случае толерантностей является статистика . Статистики и играют ту же роль для толерантностей, что для ранжировок, однако математико-статистическая теория в случае толерантностей гораздо проще, чем для ранжировок.
, называемый также коэффициентом конкордации [
[
2.1
]
, табл.6.10]. Его распределение затабулировано в предположении равномерности распределения на пространстве ранжировок (без связей). Непосредственным аналогом в случае толерантностей является статистика . Статистики и играют ту же роль для толерантностей, что для ранжировок, однако математико-статистическая теория в случае толерантностей гораздо проще, чем для ранжировок.
Обобщением равномерно распределенных толерантностей являются толерантности с независимыми связями. В этой постановке предполагается, что 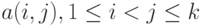 , - независимые случайные величины, принимающие значения 0 и 1. Обозначим
, - независимые случайные величины, принимающие значения 0 и 1. Обозначим 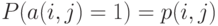 . Тогда
. Тогда  . Таким образом, распределение толерантности с независимыми связями задается нечеткой толерантностью, т.е. вектором
. Таким образом, распределение толерантности с независимыми связями задается нечеткой толерантностью, т.е. вектором
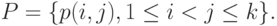
Пусть имеется независимых случайных толерантностей с независимыми связями, распределения которых задаются векторами 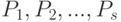 соответственно. Рассмотрим проверку гипотезы согласованности
соответственно. Рассмотрим проверку гипотезы согласованности

Она является более слабой, чем гипотеза равномерности
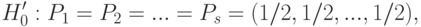 и (см. выше).
и (см. выше).Пусть сначала  . Тогда
. Тогда
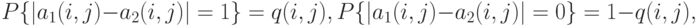
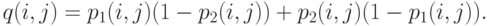
Следовательно, расстояние 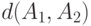 между двумя случайными толерантностями с независимыми связями есть сумма
между двумя случайными толерантностями с независимыми связями есть сумма 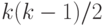 независимых случайных величин, принимающих значения 0 и 1, причем математическое ожидание и дисперсия таковы:
независимых случайных величин, принимающих значения 0 и 1, причем математическое ожидание и дисперсия таковы:
 |
( 2) |
Пусть . Если 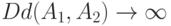 , то условие Линденберга Центральной предельной теоремы теории вероятностей выполнено (см.
"Теоретическая база прикладной статистики"
), и распределение нормированного расстояния
, то условие Линденберга Центральной предельной теоремы теории вероятностей выполнено (см.
"Теоретическая база прикладной статистики"
), и распределение нормированного расстояния
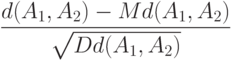 |
( 3) |
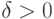 такое, что при всех
такое, что при всех 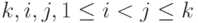 , вероятности
, вероятности 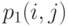 и
и 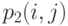 лежат внутри интервала
лежат внутри интервала 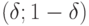 , то
, то 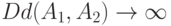 .
.Соотношения (2), (3) и им подобные позволяют рассчитать мощность критериев, основанных на статистиках и , при , подобно тому, как это сделано в [
[
1.15
]
, гл.4.5]. Поскольку подобные расчеты не требуют новых идей, не будем приводить их здесь.
Обычно 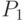 и
и 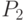 неизвестны. Для проверки гипотезы
неизвестны. Для проверки гипотезы  в некоторых случаях можно порекомендовать отвергать гипотезу на уровне значимости
в некоторых случаях можно порекомендовать отвергать гипотезу на уровне значимости  , если
, если 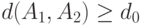 , где
, где 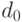 есть
есть  -квантиль распределения расстояния между двумя независимыми равномерно распределенными случайными толерантностями, т.е. квантиль биномиального распределения . Укажем достаточные условия такой рекомендации.
-квантиль распределения расстояния между двумя независимыми равномерно распределенными случайными толерантностями, т.е. квантиль биномиального распределения . Укажем достаточные условия такой рекомендации.
Пусть
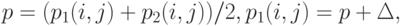
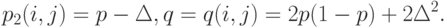 |
( 4) |
Если существует число такое, что
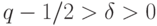 |
( 5) |
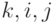 , то гипотеза будет отвергаться с вероятностью, стремящейся к 1 при . Из (4) следует, что при фиксированном существует
, то гипотеза будет отвергаться с вероятностью, стремящейся к 1 при . Из (4) следует, что при фиксированном существует  такое, что выполнено (5), тогда и только тогда, когда
такое, что выполнено (5), тогда и только тогда, когда 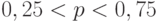 .
.Своеобразие постановки задачи проверки гипотезы состоит в том, что при росте число неизвестных параметров, т.е. координат векторов 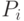 , растет пропорционально объему данных. Поэтому и столь далекая от оптимальности процедура, как описанная в двух предыдущих абзацах, представляет некоторый практический интерес. Для случая
, растет пропорционально объему данных. Поэтому и столь далекая от оптимальности процедура, как описанная в двух предыдущих абзацах, представляет некоторый практический интерес. Для случая  в теории люсианов (11.3) разработаны методы проверки гипотезы согласованности
в теории люсианов (11.3) разработаны методы проверки гипотезы согласованности 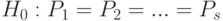 .
.
Нахождение группового мнения. Пусть - случайные толерантности, описывающие мнения экспертов. Для нахождения группового мнения будем использовать медиану Кемени, т.е. эмпирическое среднее относительно расстояния, введенного в
"Различные виды статистических данных"
. Медианой Кемени является

Легко видеть, что 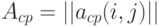 удовлетворяет условию:
удовлетворяет условию: 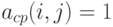 , если
, если
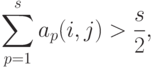
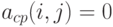 , если
, если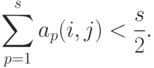
Следовательно, при нечетном групповое мнение 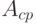 определяется однозначно. При четном неоднозначность возникает в случае
определяется однозначно. При четном неоднозначность возникает в случае

Тогда медиана Кемени - не одна толерантность, а множество толерантностей, минимум суммы расстояний достигается и при , и при .
Асимптотическое поведение группового мнения (медианы Кемени для толерантностей) вытекает из общих результатов о законах больших чисел в пространствах произвольной природы ( "Описание данных" ), поэтому рассматривать его здесь нет необходимости.
Дихотомические (бинарные) признаки в классической асимптотике. Многое в предыдущем изложении определялось спецификой толерантностей. В частности, особая роль равномерности распределения на множестве всех толерантностей оправдывала специальное рассмотрение статистик и ; аксиоматически введенное расстояние 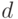 между толерантностями играло важную роль в приведенных выше результатах. Однако модель толерантностей с независимыми связями уже меньше связана со спецификой толерантностей. В ней толерантности можно рассматривать просто как частный случай люсианов. Широко применяется следующая модель порождения данных.
между толерантностями играло важную роль в приведенных выше результатах. Однако модель толерантностей с независимыми связями уже меньше связана со спецификой толерантностей. В ней толерантности можно рассматривать просто как частный случай люсианов. Широко применяется следующая модель порождения данных.
Пусть - независимые люсианы. Это значит, что статистические данные имеют вид
 |
( 6) |
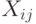 - независимые в совокупности испытания Бернулли с вероятностями успеха
- независимые в совокупности испытания Бернулли с вероятностями успеха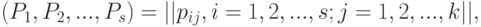 |
( 7) |
- вектор вероятностей, описывающий распределение люсиана 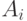 . Особое значение имеют одинаково распределенные люсианы, для которых
. Особое значение имеют одинаково распределенные люсианы, для которых 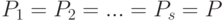 , где символом
, где символом 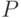 обозначен общий вектор вероятностей.
обозначен общий вектор вероятностей.Как обычно в математической статистике, содержательные результаты при изучении модели (6) - (7) можно получить в асимптотических постановках. При этом есть два принципиально разных предельных перехода: 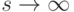 и . Первый из них - традиционный: число неизвестных параметров постоянно, объем выборки растет. Во втором число параметров растет, объем выборки остается постоянным, но общий объем данных
и . Первый из них - традиционный: число неизвестных параметров постоянно, объем выборки растет. Во втором число параметров растет, объем выборки остается постоянным, но общий объем данных  растет пропорционально числу неизвестных параметров. Аналогом является асимптотическое изучение коэффициентов ранговой корреляции Кендалла и Спирмена: число ранжировок, т.е. объем выборки, постоянно (и равно 2), а число ранжируемых объектов растет.
растет пропорционально числу неизвестных параметров. Аналогом является асимптотическое изучение коэффициентов ранговой корреляции Кендалла и Спирмена: число ранжировок, т.е. объем выборки, постоянно (и равно 2), а число ранжируемых объектов растет.
Вторая постановка изучается в следующем параграфе, посвященном люсианам. Некоторые задачи в первой постановке рассмотрим здесь.
Случайные толерантности используются, в частности, для оценки нечетких толерантностей [
[
1.15
]
]. Для описания результатов опроса группы экспертов о сходстве объектов строят нечеткую толерантность 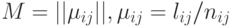 , где
, где 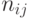 - число ответов о сходстве -го и -го объектов, а
- число ответов о сходстве -го и -го объектов, а 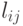 - число положительных ответов из них. Если эксперты действуют в соответствии с единым вектором параметров , то
- число положительных ответов из них. Если эксперты действуют в соответствии с единым вектором параметров , то  - состоятельная оценка для . Следующий вопрос при таком подходе - верно ли, что две группы экспертов "думают одинаково", т.е. используют совпадающие вектора ? Рассмотрим эту постановку на более общем языке люсианов.
- состоятельная оценка для . Следующий вопрос при таком подходе - верно ли, что две группы экспертов "думают одинаково", т.е. используют совпадающие вектора ? Рассмотрим эту постановку на более общем языке люсианов.
Пусть 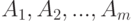 и
и 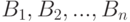 - независимые в совокупности люсианы, одинаково распределенные в каждой группе с параметрами
- независимые в совокупности люсианы, одинаково распределенные в каждой группе с параметрами 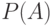 и
и 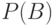 соответственно. Требуется проверить гипотезу
соответственно. Требуется проверить гипотезу  . Естественным является переход к пределу при
. Естественным является переход к пределу при 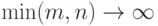 .
.
Пусть гипотеза справедлива. Предположим, что 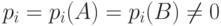 при всех
при всех  . (Разбор нарушений этого условия очевиден.) Пусть
. (Разбор нарушений этого условия очевиден.) Пусть 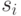 - число единиц на -м месте в первой группе люсианов, а
- число единиц на -м месте в первой группе люсианов, а 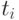 - во второй. Рассмотрим случайные величины
- во второй. Рассмотрим случайные величины
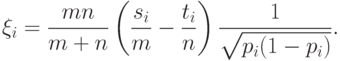 |
( 8) |
Они независимы в совокупности. В соответствии с результатами
"Теоретическая база прикладной статистики"
распределения 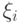 при
при 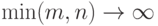 сходятся к стандартному нормальному распределению с математическим ожиданием 0 и дисперсией 1. Эти свойства сохраняются при замене
сходятся к стандартному нормальному распределению с математическим ожиданием 0 и дисперсией 1. Эти свойства сохраняются при замене 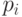 в (8) на состоятельные оценки, построенные по статистическим данным, соответствующим -му месту. Будем использовать эффективную оценку [
[
12.10
]
, с.529]
в (8) на состоятельные оценки, построенные по статистическим данным, соответствующим -му месту. Будем использовать эффективную оценку [
[
12.10
]
, с.529]
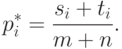 |
( 9) |
Подставим (9) в (8), получим статистики
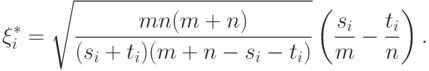
Полученные статистики можно использовать для проверки рассматриваемой гипотезы, например, с помощью критериев, основанных на статистиках
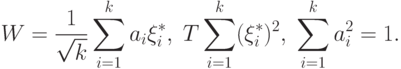
С помощью результатов
"Теоретическая база прикладной статистики"
получаем, что имеет в пределе при стандартное нормальное распределение, а  - распределение хи-квадрат с степенями свободы.
- распределение хи-квадрат с степенями свободы.
Рассмотрим распределение статистики при альтернативных гипотезах. Положим
\eta_{1m}^i=
\frac{\sqrt{m}\left(\frac{s_i}{m}-p_i(A)\right)}{\sqrt{p_i(A)(1-p_i(A))}},\;
\eta_{2n}^i=
\frac{\sqrt{n}\left(\frac{t_i}{n}-p_i(B)\right)}{\sqrt{p_i(B)(1-p_i(B))}}.
Эти случайные величины независимы, распределение каждой из них при сходится к стандартному нормальному распределению. Поскольку
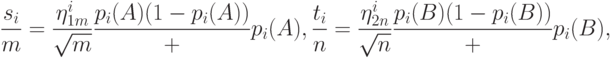
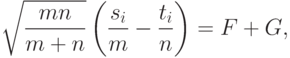
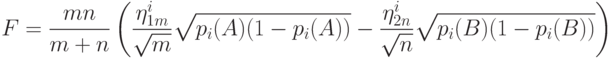
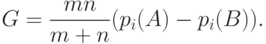
В силу результатов
"Теоретическая база прикладной статистики"
распределение  при сближается с нормальным распределением, математическое ожидание которого равно 0, а дисперсия
при сближается с нормальным распределением, математическое ожидание которого равно 0, а дисперсия
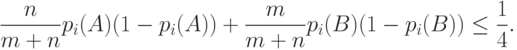
Поэтому, чтобы получить собственное (т.е. невырожденное) распределение при альтернативах, естественно рассмотреть модель
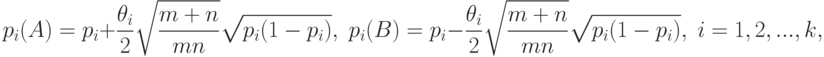
 - некоторые фиксированные числа. Тогда при оценки
- некоторые фиксированные числа. Тогда при оценки 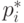 из (9) сходятся к и
из (9) сходятся к и 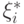 являются независимыми асимптотически нормальными случайными величинами с математическими ожиданиями и единичными дисперсиями. Опираясь на результаты
"Теоретическая база прикладной статистики"
, заключаем, что распределение статистики сходится к нормальному распределению с математическим ожиданием
являются независимыми асимптотически нормальными случайными величинами с математическими ожиданиями и единичными дисперсиями. Опираясь на результаты
"Теоретическая база прикладной статистики"
, заключаем, что распределение статистики сходится к нормальному распределению с математическим ожиданием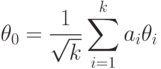
Если в последней формуле 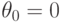 , то асимптотическое распределение таково же, как и в случае справедливости нулевой гипотезы. От указанного недостатка свободна статистика . Тем же путем, как и для , получаем, что при распределение сходится к нецентральному хи-квадрат распределению с степенями свободы и параметром нецентральности
, то асимптотическое распределение таково же, как и в случае справедливости нулевой гипотезы. От указанного недостатка свободна статистика . Тем же путем, как и для , получаем, что при распределение сходится к нецентральному хи-квадрат распределению с степенями свободы и параметром нецентральности
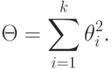
Можно рассматривать ряд других задач, например, проверку совпадения параметров для нескольких групп люсианов (аналог дисперсионного анализа), установление зависимости от (аналог регрессионного анализа), отнесение вновь поступающего люсиана к одной из групп (задача диагностики - аналог дискриминантного анализа; представляет интерес, например, при применении тестов типа MMPI оценки психического состояния личности) и т.д. Однако принципиальных трудностей на пути развития соответствующих методов не видно, и мы не будем их здесь рассматривать. Создание соответствующих алгоритмов проводится специалистами по прикладной статистике в соответствии с непосредственными заказами пользователей.
Анастасия Маркова