|
поддерживаю выше заданые вопросы
|
Спонсор: Intel
Вы можете этот курс.
Нижегородский государственный университет им. Н.И.Лобачевского
Опубликован: 02.10.2012 | Доступ: свободный | Студентов: 1754 / 201 | Длительность: 17:47:00
Специальности: Программист
Теги:
Лекция 5:
Введение в технологии параллельного программирования (MPI)
5.5. Производные типы данных в MPI
Во всех ранее рассмотренных примерах использования функций передачи данных предполагалось, что сообщения представляют собой некоторый непрерывный вектор элементов предусмотренного в MPI типа (список имеющихся в MPI типов представлен в табл. 5.1). Понятно, что в общем случае необходимые к пересылке данные могут рядом не располагаться и состоять из разного типа значений. Конечно, и в таких ситуациях разрозненные данные могут быть переданы с использованием нескольких сообщений, но такой способ решения не будет являться эффективным в силу накопления латентности множества выполняемых операций передачи данных. Другой возможный подход может состоять в предварительной упаковке передаваемых данных в формат того или иного непрерывного вектора, однако и здесь появляются лишние операции копирования данных, да и понятность таких операций передачи окажется далека от желаемой.
Для обеспечения бoльших возможностей при определении состава передаваемых сообщений в MPI предусмотрен механизм так называемых производных типов данных. Далее будут даны основные понятия используемого подхода, приведены возможные способы конструирования производных типов данных и рассмотрены функции упаковки и распаковки данных.
5.5.1. Понятие производного типа данных
В самом общем виде под производным типом данных в MPI можно понимать описание набора значений предусмотренного в MPI типа, причем в общем случае описываемые значения не обязательно непрерывно располагаются в памяти. Задание типа в MPI принято осуществлять при помощи карты типа (type map) в виде последовательности описаний входящих в тип значений, каждое отдельное значение описывается указанием типа и смещения адреса месторасположения от некоторого базового адреса, т.е.

Часть карты типа с указанием только типов значений именуется в MPI сигнатурой типа:
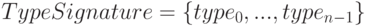
Сигнатура типа описывает, какие базовые типы данных образуют некоторый производный тип данных MPI и, тем самым, управляет интерпретацией элементов данных при передаче или получении сообщений. Смещения карты типа определяют, где находятся значения данных.
Поясним рассмотренные понятия на следующем примере. Пусть в сообщение должны входить значения переменных:
double a; /* адрес 24 */ double b; /* адрес 40 */ int n; /* адрес 48 */
Тогда производный тип для описания таких данных должен иметь карту типа следующего вида:
{(MPI_DOUBLE,0),
(MPI_DOUBLE,16),
(MPI_INT,24)
}Дополнительно для производных типов данных в MPI используется следующий ряд новых понятий:
-
нижняя граница типа
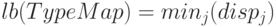
-
верхняя граница типа

-
протяженность типа
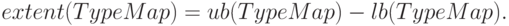
Согласно определению нижняя граница есть смещение для первого байта значений рассматриваемого типа данных. Соответственно верхняя граница представляет собой смещение для байта, располагающегося вслед за последним элементом рассматриваемого типа данных. При этом величина смещения для верхней границы может быть округлена вверх с учетом требований выравнивания адресов. Так, одно из самых общих требований, которые налагают реализации языков C и Fortran, состоит в том, чтобы адрес элемента был кратен длине этого элемента в байтах. Например, если тип int занимает четыре байта, то адрес на элемент типа int должен нацело делиться на четыре. Именно это требование и отражается в определении верхней границы типа данных MPI. Поясним данный момент на ранее рассмотренном примере набора переменных a,b и n, для которого нижняя граница равна 0, а верхняя граница принимает значение 32(величина округления 6 или 4 в зависимости от размера типа int). Здесь следует отметить, что требуемое выравнивание определяется по типу первого элемента данных в карте типа.
Следует также указать на различие понятий протяженности и размера типа. Протяженность – это размер памяти в байтах, который нужно отводить для одного элемента производного типа. Размер типа данных - это число байтов, которые занимают данные (разность между адресами последнего и первого байтов данных). Различие в значениях протяженности и размера опять же в величине округления для выравнивания адресов. Так, в рассматриваемом примере размер типа равен 28, а протяженность – 32 (предполагается, что тип int занимает четыре байта). Для получения значения протяженности и размера типа в MPI предусмотрены функции:
int MPI_Type_extent( MPI_Datatype type, MPI_Aint *extent ), int MPI_Type_size ( MPI_Datatype type, MPI_Aint *size ).
Определение нижней и верхней границ типа может быть выполнено при помощи функций:
int MPI_Type_lb ( MPI_Datatype type, MPI_Aint *disp ), int MPI_Type_ub( MPI_Datatype type, MPI_Aint *disp ).
Важной и необходимой при конструировании производных типов является функция получения адреса переменной:
int MPI_Address ( void *location, MPI_Aint *address )
(следует отметить, что данная функция является переносимым вариантом средств получения адресов в алгоритмических языках C и Fortran).
5.5.2. Способы конструирования производных типов данных
Для снижения сложности в MPI предусмотрено несколько различных способроизводых типов:
- Непрерывный способ позволяет определить непрерывный набор элементов существующего типа как новый производный тип
- Векторный способ обеспечивает создание нового производного типа как набора элементов существующего типа, между элементами которого существуют регулярные промежутки по памяти. При этом,размер промежутков задается в числе элементов исходного типа, в то время, как в варианте H-векторного способа этот размер указывается в байтах,
- Индексный способ отличается от векторного метода тем, что промежутки между элементами исходного типа могут иметь нерегулярный характер,
- Структурный способ обеспечивает самое общее описание производного типа через явное указание карты создаваемого типа данных.
Далее перечисленные способы конструирования производных типов данных будут рассмотрены более подробно.
5.5.2.1 Непрерывный способ конструирования
При непрерывном способе конструирования производного типа данных в MPI используется функция:
int MPI_Type_contiguous(int count,MPI_Data_type oldtype,MPI_Datatype *newtype).
Как следует из описания, новый тип newtype создается как count элементов исходного типа oldtype. Например, если исходный тип данных имеет карту типа
{ (MPI_INT,0),(MPI_DOUBLE,8) }, то вызов функции MPI_Type_contiguous с параметрами
MPI_Type_contiguous (2, oldtype,&newtype);
приведет к созданию типа данных с картой типа
{ (MPI_INT,0),(MPI_DOUBLE,8),(MPI_INT,16),(MPI_DOUBLE,24) }.В определенном плане наличие непрерывного способа конструирования является избыточным, покольку использование аргумента count в процедурах MPI равносильно использованию непрерывного типа данных такого же размера.
5.5.2.2 Векторный способ конструирования
При векторном способе конструирования производного типа данных в MPI используются функции
int MPI_Type_vector ( int count, int blocklen, int stride, MPI_Data_type oldtype, MPI_Datatype *newtype ),
где count – количество блоков, blocklen – размер каждого блока, stride – количество элементов, расположенных между двумя соседними блоками oldtype - исходный тип данных, newtype - новый определяемый тип данных.
int MPI_Type_hvector ( int count, int blocklen, MPI_Aint stride, MPI_Data_type oldtype, MPI_Datatype *newtype ).
Отличие способа конструирования, определяемого функцией MPI_Type_hvector, состоит лишь в том, что параметр stride для определения интервала между блоками задается в байтах, а не в элементах исходного типа данных.
Как следует из описания, при векторном способе новый производный тип создается как набор блоков из элементов исходного типа,при этом между блоками могут иметься регулярные промежутки по памяти.
Приведем несколько примеров использования данного способа конструирования типов:
- Конструирование типа для выделения половины (только четных или только нечетных) строк матрицы размером nxn: MPI_Type_vector ( n/2, n, 2*n, &StripRowType, &ElemType ),
- Конструирование типа для выделения столбца матрицы размером nxn: MPI_Type_vector ( n, 1, n, &ColumnType, &ElemType ),
- Конструирование типа для выделения главной диагонали матрицы размером nxn: MPI_Type_vector ( n, 1, n+1, &DiagonalType, &ElemType).
С учетом характера приводимых примеров можно упомянуть имеющуюся в MPI возможность создания производных типов для описания подмассивов многомерных массивов при помощи функции (данная функция предусматривается стандартом MPI-2):
int MPI_Type_create_subarray ( int ndims, int *sizes, int *subsizes, int *starts, int order, MPI_Data_type oldtype, MPI_Datatype *newtype ),
где ndims – размерность массива, sizes – количество элементов в каждой размерности исходного массива, subsizes – количество элементов в каждой размерности определяемого подмассива, starts – индексы начальных элементов в каждой размерности определяемого подмассива, order - параметр для указания необходимости переупорядочения, oldtype - тип данных элементов исходного массива, newtype - новый тип данных для описания подмассива.
5.5.2.3 Индексный способ конструирования
При индексном способе конструирования производного типа данных в MPI используются функции:
int MPI_Type_indexed ( int count, int blocklens[], int indices[], MPI_Data_type oldtype, MPI_Datatype *newtype ), где - count – количество блоков, - blocklens – количество элементов в каждов блоке, - indices – смещение каждого блока от начала типа (в количестве элементов исходного типа), - oldtype - исходный тип данных, - newtype - новый определяемый тип данных. int MPI_Type_hindexed ( int count, int blocklens[], MPI_Aint indices[], MPI_Data_type oldtype, MPI_Datatype *newtype )
Как следует из описания, при индексном способе новый производный тип создается как набор блоков разного размера из элементов исходного типа, при этом между блоками могут иметься разные промежутки по памяти. Для пояснения данного способа можно привести пример конструирования типа для описания верхней треугольной матрицы размером nxn:
// конструирование типа для описания верхней треугольной матрицы for ( i=0, i<n; i++ ) {
blocklens[i] = n - i;
indices[i] = i * n + i;
}
MPI_Type_indexed ( n, blocklens, indices, &UTMatrixType, &ElemType ).Как и ранее, способ конструирования, определяемый функцией MPI_Type_hindexed, отличается тем, что элементы indices для определения интервалов между блоками задаются в байтах, а не в элементах исходного типа данных.
Следует отметить, что существует еще одна дополнительная функция MPI_Type_create_indexed_block индексного способа конструирования для определения типов с блоками одинакового размера (данная функция предусматривается стандартом MPI-2).
5.5.2.4 Структурный способ конструирования
Как отмечалось ранее, структурный способ является самым общим методом конструирования производного типа данных при явном задании соответствующей карты типа. Использование такого способа производится при помощи функции:
int MPI_Type_struct ( int count, int blocklens[], MPI_Aint indices[], MPI_Data_type oldtypes[], MPI_Datatype *newtype ),
где count – количество блоков, blocklens – количество элементов в каждов блоке, indices – смещение каждого блока от начала типа (в байтах), oldtypes - исходные типы данных в каждом блоке в отдельности, newtype - новый определяемый тип данных.
Как следует из описания, структурный способ дополнительно к индексному методу позволяет указывать типы элементов для каждого блока в отдельности.
5.5.3. Объявление производных типов и их удаление
Рассмотренные в предыдущем пункте функции конструирования позволяют определить производный тип данных. Дополнительно перед использованием созданный тип должен быть объявлен при помощи функции:
int MPI_Type_commit (MPI_Datatype *type ).
При завершении использования производный тип должен быть аннулирован при помощи функции:
int MPI_Type_free (MPI_Datatype *type ).
5.5.4. Формирование сообщений при помощи упаковки и распаковки данных
Наряду с рассмотренными в п. 5.5.2 методами конструирования производных типов в MPI предусмотрен и явный способ сборки и разборки сообщений, содержащих значения разных типов и располагаемых в разных областях памяти.
Для использования данного подхода должен быть определен буфер памяти достаточного размера для сборки сообщения. Входящие в состав сообщения данные должны быть упакованы в буфер при помощи функции:
int MPI_Pack ( void *data, int count, MPI_Datatype type, void *buf, int bufsize, int *bufpos, MPI_Comm comm),
где data – буфер памяти с элементами для упаковки, count – количество элементов в буфере, type – тип данных для упаковываемых элементов, buf - буфер памяти для упаковки, buflen – размер буфера в байтах, bufpos – позиция для начала записи в буфер (в байтах от начала буфера), comm - коммуникатор для упакованного сообщения.
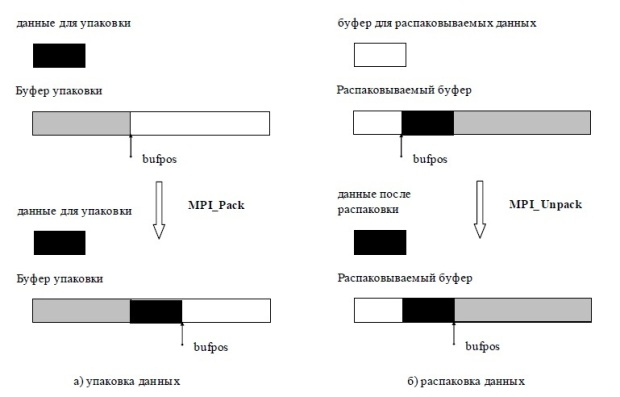
Функция MPI_Pack упаковывает count элементов из буфера data в буфер упаковки buf, начиная с позиции bufpos. Общая схема процедуры упаковки показана на рис. 5.8а.
Начальное значение переменной bufpos должно быть сформировано до начала упаковки и далее устанавливается функцией MPI_Pack. Вызов функции MPI_Pack осуществляется последовательно для упаковки всех необходимых данных. Так, для ранее рассмотренного примера набора переменных a,b и n, для их упаковки необходимо выполнить:
bufpos = 0; MPI_Pack(a,1,MPI_DOUBLE,buf,buflen,&bufpos,comm); MPI_Pack(b,1,MPI_DOUBLE,buf,buflen,&bufpos,comm); MPI_Pack(n,1,MPI_INT,buf,buflen,&bufpos,comm);
Для определения необходимого размера буфера для упаковки может быть использована функция:
int MPI_Pack_size (int count, MPI_Datatype type, MPI_Comm comm, int *size),
которая в параметре size указывает необходимый размер буфера для упаковки count элементов типа type.
После упаковки всех необходимых данных подготовленный буфер может быть использован в функциях передачи данных с указанием типа MPI_PACKED.
После получения сообщения с типом MPI_PACKED данные могут быть распакованы при помощи функции:
int MPI_Unpack (void *buf, int bufsize, int *bufpos, void *data, int count, MPI_Datatype type, MPI_Comm comm),
где buf - буфер памяти с упакованными данными, buflen – размер буфера в байтах, bufpos – позиция начала данных в буфере (в байтах от начала буфера), data – буфер памяти для распаковываемых данных, count – количество элементов в буфере, type – тип распаковываемых данных, comm - коммуникатор для упакованного сообщения.
Функция MPI_Unpack распаковывает начиная с позиции bufpos очередную порцию данных из буфера buf и помещает распакованные данные в буфер data. Общая схема процедуры распаковки показана на рис. 5.8б.
Начальное значение переменной bufpos должно быть сформировано до начала распаковки и далее устанавливается функцией MPI_Unpack. Вызов функции MPI_Unpack осуществляется последовательно для распаковки всех упакованных данных, при этом порядок распаковки должен соответствовать порядку упаковки. Так, для ранее рассмотренного примера упаковки для распаковки упакованных данных необходимо выполнить:
bufpos = 0; MPI_Pack(buf,buflen,&bufpos,a,1,MPI_DOUBLE,comm); MPI_Pack(buf,buflen,&bufpos,b,1,MPI_DOUBLE,comm); MPI_Pack(buf,buflen,&bufpos,n,1,MPI_INT,comm);
В заключение выскажем ряд рекомендаций по использованию упаковки для формирования сообщений. Поскольку такой подход приводит к появлению дополнительных действий по упаковке и распаковке данных, то данный способ может быть оправдан при сравнительно небольших размерах сообщений и при малом количестве повторений. Упаковка и распаковка может оказаться полезной при явном использовании буферов для буферизованного способа передачи данных.
Павел Каширин
|
Скачал архив и незнаю как ничать изучать материал. Видео не воспроизводится (скачено очень много кодеков, различных плееров -- никакого эффекта. Максимум видно часть изображения без звука). При старте ReplayMeeting и Start в браузерах google chrome, ie возникает script error с невнятным описанием. В firefox ситуация еще интереснее. Выводится: Meet Now: Кукаева Светлана Александровна. Meeting Start Time: 09.10.2012, 16:58:04 Downloading... Your Web browser is not configured to play Windows Media audio/video files. Make sure the features are enabled and available.
|