|
Не обнаружил проекты, которые используются в примерах в лекции, также не увидел список задач. |
Тверской государственный университет
Опубликован: 22.11.2005 | Доступ: свободный | Студентов: 30494 / 1881 | Оценка: 4.31 / 3.69 | Длительность: 28:26:00
ISBN: 978-5-9556-0050-5
Тема: Программирование
Специальности: Программист, Архитектор программного обеспечения
Теги:
Лекция 15:
Регулярные выражения
Пример "чет и нечет"
Не всякий класс языков можно описать с помощью регулярных выражений. И даже тогда, когда такая возможность есть, могут потребоваться определенные усилия для корректной записи соответствующего регулярного выражения. Рассмотрим, например, язык L1 в алфавите T={0,1}, которому принадлежат пустое слово и слова, содержащие четное число нулей и четное число единиц. В качестве другого примера рассмотрим язык L2, отличающийся от первого тем, что в нем число единиц нечетно. Оба языка можно задать регулярными выражениями, но корректная запись непроста и требует определенного навыка. Давайте запишем регулярные выражения, определяющие эти языки, и покажем, что C# справляется с проблемой их распознавания. Вот регулярное выражение, описывающее первый язык:
(00|11)*((01|10)(00|11)*(01|10)(00|11)*)*
Дадим содержательное описание этого языка. Слова языка представляют возможно пустую последовательность из пар одинаковых символов. Далее может идти последовательность, начинающаяся и заканчивающаяся парами различающихся символов, между которыми может стоять произвольное число пар одинаковых символов. Такая группа может повторяться многократно. Регулярное выражение короче и точнее передает описываемую структуру слов языка L1.
Язык L2 описать теперь совсем просто. Его слова представляют собой единицу, окаймленную словами языка L1.
Прежде чем перейти к примеру распознавания слов языков L1 и L2, приведу процедуру FindMatches, позволяющую найти все вхождения образца в заданный текст:
void FindMatches(string str, string strpat)
{
Regex pat = new Regex(strpat);
MatchCollection matchcol =pat.Matches(str);
Console.WriteLine("Строка ={0}\tОбразец={1}",str,strpat);
Console.WriteLine("Число совпадений ={0}",matchcol.Count);
foreach(Match match in matchcol)
Console.WriteLine("Index = {0} Value = {1}, Length ={2}",
match.Index,match.Value, match.Length);
}//FindMatchesВходные аргументы у процедуры те же, что и у функции FindMatch, ищущей первое вхождение. Я не стал задавать выходных аргументов процедуры, ограничившись тем, что все результаты непосредственно выводятся на печать в самой процедуре. Выполнение процедуры, так же, как и в FindMatch, начинается с создания объекта pat класса Regex, конструктору которого передается регулярное выражение. Замечу, что класс Regex, так же, как и класс String, относится к неизменяемым (immutable) классам, поэтому для каждого нового образца нужно создавать новый объект pat.
В отличие от FindMatch, объект pat вызывает метод Matches, который определяет все вхождения подстрок, удовлетворяющих образцу, в заданный текст. Результатом выполнения метода Matches является автоматически создаваемый объект класса MatchCollection, хранящий коллекцию объектов уже известного нам класса Match, каждый из которых задает очередное вхождение. В процедуре используются свойства коллекции и ее элементов для получения в цикле по элементам коллекции нужных свойств - индекса очередного вхождения подстроки в строку, ее длины и значения.
Вот процедура, в которой многократно вызывается FindMatches для различных строк и образцов поиска:
public void TestMultiPat()
{
//поиск по образцу всех вхождений
string str,strpat,found;
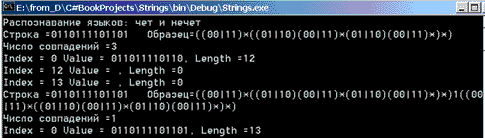
Console.WriteLine("Распознавание языков: чет и нечет");
//четное число нулей и единиц
strpat ="((00|11)*((01|10)(00|11)*(01|10)(00|11)*)*)";
str = "0110111101101";
FindMatches(str, strpat);
//четное число нулей и нечетное единиц
string strodd = strpat + "1" + strpat;
FindMatches(str, strodd);
}//TestMultiPatКоротко прокомментирую работу этой процедуры. Первые два примера связаны с распознаванием языков L1 и L2 (чет и нечет) - языков с четным числом единиц и нулей в первом случае и нечетным числом единиц во втором. Регулярные выражения, описывающие эти языки, подробно рассматривались. В полном соответствии с теорией, константы задают эти выражения. На вход для распознавания подается строка из нулей и единиц. Для языка L1 метод находит три соответствия. Первое из них задает максимально длинную подстроку, содержащую четное число нулей и единиц, и две пустые подстроки, по определению принадлежащие языку L1. Для языка L2 находится одно соответствие - это сама входная строка. Взгляните на результаты распознавания.
Пример "око и рококо"
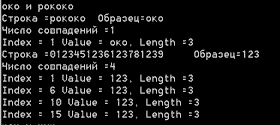
Следующий образец в нашем примере позволяет прояснить некоторые особенности работы метода Matches. Сколько раз строка "око" входит в строку "рококо" - один или два? Все зависит от того, как считать. С точки зрения метода Matches, - один раз, поскольку он разыскивает непересекающиеся вхождения, начиная очередной поиск вхождения подстроки с того места, где закончилось предыдущее вхождение. Еще один пример на эту же тему работает с числовыми строками.
Console.WriteLine("око и рококо");
strpat="око"; str = "рококо";
FindMatches(str, strpat);
strpat="123";
str= "0123451236123781239";
FindMatches(str, strpat);На рис. 15.3 показаны результаты поисков.
Пример "кок и кук"
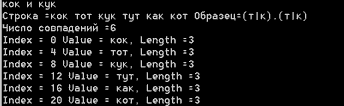
Этот пример на поиск множественных соответствий навеян словами песни Высоцкого, где говорится, что дикари не смогли распознать, где кок, а где Кук. Наше регулярное выражение также не распознает эти слова. Обратите внимание на точку в регулярном выражении, которая соответствует любому символу, за исключением символа конца строки. Все слова в строке поиска - кок, кук, кот и другие - будут удовлетворять шаблону, так что в результате поиска найдется множество соответствий.
Console.WriteLine("кок и кук");
strpat="(т|к).(т|к)";
str="кок тот кук тут как кот";
FindMatches(str, strpat);Вот результаты работы этого фрагмента кода.