Опубликован: 23.05.2008 | Доступ: свободный | Студентов: 1589 / 412 | Оценка: 4.80 / 4.10 | Длительность: 15:29:00
Специальности: Программист
Теги:
Лекция 11:
Распределенное хранение информации
Менеджер сайта – владельца исходной базы данных получает сообщение "включить данные в БД" при необходимости корректировки копий. Менеджер заносит соответствующую запись "начало транзакции" в свой журнал, готовит структуру данных (  ) для занесения в нее в будущем информации о готовности периферийных сайтов и рассылает всем сообщение "приготовиться к изменениям". Кроме этого, менеджер устанавливает предельное время ( T ) для проведения всего процесса.
) для занесения в нее в будущем информации о готовности периферийных сайтов и рассылает всем сообщение "приготовиться к изменениям". Кроме этого, менеджер устанавливает предельное время ( T ) для проведения всего процесса.
Менеджеры mj сайтов начинают присылать сообщения о своей готовности. Идентификаторы этих сайтов заносятся в множество n. Если все сайты готовы, то при приходе последнего сообщения выполнится условие L = S, т.е. множество сайтов, сообщивших о своей готовности, совпадает с множеством всех сайтов.
После этого менеджер M отправляет всем mj сообщение "общее обновление". Далее идет процесс, похожий на предыдущий. Только теперь менеджеры mj проводят обновления и сообщают об этом словом "выполнено". Если все выполнят обновления, то транзакция завершается.
Если какой-либо из сайтов не готов или не выполнил обновление, то менеджер M дает команду "общий возврат", отменяющую транзакцию. После отмены он ожидает подтверждений о принятии отмены от менеджеров копий базы данных.
Рутины менеджеров копий:
routine m
initial
состояние сайта := "готов"
endi
event
case message = "приготовиться к изменениям":
if test(состояние сайта) = "готов" then
begin
write("начинается обновление");
блокировка доступа к копии БД;
out("готов");
schedule (TimeOut, T)
end
else
begin
write("не готов"); out("не готов"); откат транзакции
end
message = "общее обновление":
if test(состояние сайта) = "готов" then
begin
write("произведено обновление"); put; out("выполнено");
end
else
begin
write("не готов"); out("не выполнено"); откат транзакции
end
message = "общий возврат":
begin
write("отказ инициатора обновления"); откат транзакции; out("отказ принят");
состояние сайта := "готов"
end
endc
ende;
event TimeOut;
состояние сайта := "не готов"; снятие блокировки доступа к копии БД
ende.
11.2.
Переменная "состояние сайта" является" на каждом сайте разделяемой между менеджером копии и другими управляющими программами. Первоначально менеджер копии mj устанавливает ее значение как "готов". Впоследствии другие управляющие программы могут присваивать ей как значение "готов", так и значение "не готов".
Таким образом, при получении пакета изменяемых данных и сообщения (message) "приготовиться к изменениям" от менеджера M состояния сайтов с копиями могут быть различными.
В случае готовности менеджер сайта с копией БД заносит в свой журнал запись "начинается обновление", блокирует доступ пользователей к копии БД, сообщает менеджеру M о своей готовности и включает "часы" для ожидания в течение времени T. Если транзакция не завершается почему-либо в течение этого времени, то состояние сайта меняется на "не готов" и блокировка доступа к копии БД для пользователей снимается. В дальнейшем готовность может быть вновь установлена, но в данном протоколе это действие не отражено.
Приведенный протокол, очевидно, допускает блокировки обновления данных отдельными сайтами, что является его недостатком. Избежать блокировок можно специальными методами, например, применением трехфазной фиксацией транзакций.
Схемы владения данными в распределенной БД
Выше, рассматривая распределенную базу данных, состоящую из локальных сайтов, мы неявно предполагали, что для каждой единицы данных существует вполне определенный единственный сайт, владеющий этими данными. Т.е. что каждый источник данных приписан одному сайту.
Однако, реальная ситуация не всегда соответствует этой схеме. Существуют мобильные пользователи (и источники данных), перемещающиеся от сайта к сайту. Отдельные данные могут передаваться с сайта на сайт в соответствии с некоторыми бизнес-процессами. При этом происходит не копирование, а именно передача, без сохранения данных на старом сайте.
В литературе рассматриваются несколько схем владения данными:
- ведущий/ведомый;
- рабочий поток;
- симметричная репликация.
Схема "ведущий/ведомый" фактически уже была описана. Она заключается в том, что у любых данных имеется единственный владелец (ведущий), остальные пользователи этих данных (ведомые) производят изменения в своих копиях, может быть, асинхронно после изменения данных ведущим. Причем задержка в изменениях для разных пользователей может быть различной и даже, в крайнем случае, не производиться. Пример такого рода связан с использованием информации из Интернета. Полученная копия какого-либо документа с некоторого сайта используется в текущей работе, и в дальнейшем оказывается не нужна пользователю, даже если на сайте этот документ изменился.
Схема "рабочий поток" ориентирована на базы данных, обслуживающие бизнес-процессы. Бизнес-процесс может исполняться несколькими работниками организации, располагающими на различных сайтах. Комплект данных, сопровождающий бизнес-процесс, претерпевает изменения во время выполнения технологических операций процесса. Кроме этого, комплект данных передается с сайта на сайт, где и выполняются эти технологические операции. Логично признать, что при этом перемещении меняются и владельцы комплекта данных.
В схеме "рабочий поток" у любых данных, также как и в схеме "ведущий/ведомый", имеется единственный владелец. Однако в схеме "ведущий/ведомый" – это постоянное владение, а в схеме "рабочий поток" – временное владение, со сменой владельца. Но там и там в любой момент времени только один сайт имеет право менять конкретные данные, остальные могут только читать эти данные.
В схеме "симметричной репликации" все сайты, использующие копии БД, равноправны, т.е. все являются, одновременно, и владельцами и пользователями. Такая схема наиболее динамична и удобна для работников организации, выполняющих действия с одними и теми же записями в распределенной базе данных. При этом работники выступают и в качестве пользователей данных (чтение) и в качестве источников данных (запись, изменения). Каждый может изменять данные, но и каждый несет ответственность за достоверность изменений.
С точки зрения реализации схема "симметричной репликации" наиболее сложна. Она требует механизма выявления и разрешения конфликтов. Конфликты возникают при асинхронной репликации, если между двумя соседними моментами времени ti и ti+1 синхронизации копий БД пользователи, по крайней мере, на двух сайтах произвели изменения одних и тех же данных. Если, конечно, они произвели одинаковые изменения и знают об этом, то проблем нет. Но чаще изменения неодинаковы и/или без взаимного информирования (по какому-либо каналу передачи данных, не входящему в систему).
Примеры конфликтов.
- На двух сайтах внесли различные записи под одним и тем же номером в структуру данных FIFO – очередь ("лист ожидания"). Кто "стоит в очереди" раньше?
- В некоторое поле, предназначенное для накопления суммы, и имевшее после синхронизации значение
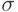 на двух сайтах добавили слагаемые
на двух сайтах добавили слагаемые 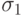 и
и 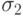 , соответственно. Как провести обновление данных при очередной синхронизации копий? А если преобразование было более сложным, чем суммирование?
, соответственно. Как провести обновление данных при очередной синхронизации копий? А если преобразование было более сложным, чем суммирование? - На двух сайтах удалили различные записи. При очередной синхронизации нужно принимать во внимание оба удаления или только одно? Если одно, то которое?
Применяются следующие механизмы разрешения:
- Установление для каждого сайта приоритета. При конфликте принимаются во внимание изменения, произведенные сайтом с наиболее высоким приоритетом.
- Пересчет изменений в базах. В приведенном выше примере на сайтах появились значения (
 ). При очередной синхронизации можно вычислить новое значение поля как сумму старого значения и всех приращений в копиях:
). При очередной синхронизации можно вычислить новое значение поля как сумму старого значения и всех приращений в копиях: 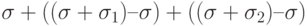 .
. - Экстремальное значение. Подобно предыдущему механизму, но для случая, когда в определенном поле фиксируется экстремальное (минимальное или максимальное) значение. В этом случае из всех копий при синхронизации выбирается копия с экстремальным значением и принимается за новое состояние базы данных (или фрагмента).
- Самое позднее изменение копии. Изменения на разных сайтах производились в разное время, следовательно, имеют различную актуальность. Естественно выбрать наиболее актуальную копию для последующей работы.
Разумеется, это только некоторые возможные механизмы. В зависимости от вида изменений на сайтах следует использовать другие механизмы, вплоть до неавтоматизированного (ручного) сравнения изменений в копиях и принятия решения по корректировке копий при синхронизации. Последний вариант может использоваться при относительно редкой синхронизации, например, раз в сутки.
Ольга Космодемьянская
|
Я прошла курс "Распределенные системы и алгоритмы". Сдала экзамен экстерном и получила диплом. Вопрос: можно ли после завершения теста посмотреть все вопросы, которые были на экзамене и все варианты ответов? Мне это необходимо для отчета преподавателю в моем ВУЗе. Заранее спасибо! |