|
При прохождении теста 1 в нем оказались вопросы, который во-первых в 1 лекции не рассматривались, во-вторых, оказалось, что вопрос был рассмаотрен в самостоятельно работе №2. Это значит, что их нужно выполнить перед прохождением теста? или это ошибка? |
Спонсор: Intel
Вы можете этот курс.
Новосибирский Государственный Университет
Опубликован: 20.08.2013 | Доступ: свободный | Студентов: 868 / 39 | Длительность: 14:11:00
Темы: Программирование, Графика и дизайн
Специальности: Программист, Системный архитектор
Теги:
Самостоятельная работа 3:
Машинное обучение
4. Программная реализация
4.1. Разработка приложения для решения задач классификации
4.1.1. Требования к приложению
В рамках данной лабораторной работы предлагается разработать приложение для решения задач классификации, предусматривающее возможность применения рассмотренных выше алгоритмов машинного обучения. К приложению предъявляются следующие требования:
- Организация диалога с пользователем для загрузки набора данных из файла с последующим выбором алгоритма обучения с учителем и его параметров.
- Обучение модели на загруженных данных.
- Вычисление ошибки классификации на обучающей и тестовой выборках.
- Визуализация результата работы алгоритмов в случае двумерного пространства признаков.
4.1.2. Структура приложения
Приложение будет состоять из набора модулей (cvsvm.cpp/h, cvdtree.cpp/h, cvrtrees.cpp/h, cvgbtrees.cpp/h), каждый из которых предназначен для работы (запрос у пользователя параметров, обучение и предсказание) рассматриваемых алгоритмов обучения, модуля вычисления ошибки классификации (errorMetrics.cpp/h), модуля визуализации данных (drawingFunctions.cpp/h) и основного модуля (main.cpp), содержащего общую логику работы программы. Основной модуль и модуль визуализации предоставляются в реализованном виде, следовательно, необходимо реализовать непосредственно работу с различными алгоритмами обучения с учителем. Далее рассматриваются интерфейсы готовых функций, а также функционал, который предлагается реализовать самостоятельно.
Модуль визуализации данных содержит функцию рисования точек из двумерного пространства признаков drawPoints:
void drawPoints(Mat & img,
const Mat & data,
const Mat & classes,
const Mat & ranges,
std::map<int, Scalar> & classColors,
int drawingMode = 0);
В качестве аргументов данная функция принимает:
- img – изображение (матрица типа CV_8UC3).
- data – матрица типа CV_32F, содержащая признаковые описания объектов выборки.
- classes – матрица типа CV_32S с номерами классов объектов выборки.
- ranges – матрица типа CV_64F, содержащая в первом столбце визуализируемый диапазон первого признака (отображаемого по оси X), а вот втором – второго.
- classColors – соответствие номеров классов и цветов точек. Если какому-либо классу не будет поставлен в соответствие цвет, то он будет сгенерирован случайным образом.
- drawingMode – тип отображаемых точек. Для рисования закрашенных точек используется drawingMode=0, для "выколотых" точек drawingMode=1, для рисования черных точек drawingMode=2. Использование данного параметра позволяет различным образом отображать точки обучающей и тестовой выборок, а также (при использовании SVM) опорных векторов.
Функция drawPartition позволяет отображать разбиение пространства признаков на области, соответствующие разным классам, путем вычисления предсказаний на равномерной сетке:
void drawPartition(Mat & img,
map<int, Scalar> & classColors,
const Mat & dataRanges,
const Size stepsNum,
const CvStatModel & model,
getPredictedClassLabel * predictLabel);
Параметры функции:
- img – изображение (матрица типа CV_8UC3).
- classColors – соответствие номеров классов и цветов точек. Если какому-либо классу не будет поставлен в соответствие цвет, то он будет сгенерирован случайным образом.
-
dataRanges – матрица типа CV_64F, содержащая в первом столбце визуализируемый диапазон первого признака (отображаемого по оси
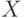 ), а вот втором – второго.
), а вот втором – второго. - stepsNum – количество узлов сетки в каждом из направлений.
- model – обученная модель для выполнения предсказаний в узлах сетки.
- predictLabel – указатель на функцию вычисления пресказаний с помощью model.
Функция getRanges предназначена для поиска матрицы минимальных и максимальных значений каждого признака в выборке data:
Mat getRanges(const Mat & data);
Функция readDatasetFromFile позволяет считать данные (обучающую и тестовую выборки) из XML- или YAML-файла.
void readDatasetFromFile(Mat & featuresTrain,
Mat & classesTrain,
Mat & featuresTest,
Mat & classesTest);
Файл должен содержать матрицы признаков объектов обучающей ("featuresTrain") и тестовой ("featuresTest") выборок и соответствующих им классов ("classesTrain" и "classesTest") в формате OpenCV. Матрицы classesTrain и classesTest должны иметь тип CV_32S, featuresTrain и featuresTest – CV_32F.
Основная логика программы сосредоточена в модуле main.cpp и выглядит следующим образом:
- В цикле пользователю предлагается загрузить данные из файла, либо применить к уже загруженным данным алгоритм обучения с учителем из списка: машина опорных векторов, дерево решений, случайный лес, градиентный бустинг деревьев решений.
- Если выбран алгоритм решения задачи классификации, у пользователя запрашиваются параметры алгоритма обучения, производится обучение и вычисление ошибок на обучающей и тестовой выборках. Если размерность пространства признаков равна двум, то данные и разбиение пространства признаков полученной моделью отображаются в новом графическом окне.
- Графические окна не обязательно закрывать перед применением другого алгоритма к тем же данным, что позволяет сравнить результаты работы различных методов. Однако при загрузке новых данных все графические окна будут закрыты автоматически.
Перейдем к рассмотрению функций, которые предлагается реализовать самостоятельно. Прежде всего, это функции, запускающие обучение моделей:
void trainSVM(const Mat & trainSamples,
const Mat & trainClasses,
const CvSVMParams & params,
CvSVM & svm);
void trainDTree(const Mat & trainSamples,
const Mat & trainClasses,
const CvDTreeParams & params,
CvDTree & dtree);
void trainRTrees(const Mat & trainSamples,
const Mat & trainClasses,
const CvRTParams & params,
CvRTrees & rtrees);
void trainGBTrees(const Mat & trainSamples,
const Mat & trainClasses,
const CvGBTreesParams & params,
CvGBTrees & gbtrees);
Данные функции находятся в файлах cvsvm.cpp, cvdtree.cpp, cvrtrees.cpp, cvgbtrees.cpp соответственно. В теле каждой функции требуется вызвать метод переданного в нее объекта для обучения модели на данных trainSamples (матрица признаковых описаний объектов) и trainClasses (матрица номеров классов) с параметрами params.
Также требуется реализация функций для предсказания:
int getSVMPrediction(const Mat & sample,
const CvStatModel & model);
int getDTreePrediction(const Mat & sample,
const CvStatModel & model);
int getRTreesPrediction(const Mat & sample,
const CvStatModel & model);
int getGBTreesPrediction(const Mat & sample,
const CvStatModel & model);
Функции, принимают признаковое описание объекта sample и обученную модель model, возвращая номер предсказанного класса. Интерфейс данных функций унифицирован для более простого подсчета ошибок на обучающей и тестовой выборках. Функции принимают объекты базового типа CvStatModel, однако, фактичеси это должны быть объекты соответствующих классов: для getSVMPrediction объект класса CvSVM, для getDTreePrediction – CvDTree и т.д.
Также предлагается реализовать функцию getSupportVectors (файл cvsvm.cpp), принимающую обученную машину опорных векторов svm и возвращающую матрицу, где каждая строка соответствует опорному вектору:
Mat getSupportVectors(const CvSVM & svm);
Функции запроса параметров каждого из рассматриваемых алгоритмов обучения предоставляются в готовом виде и рекомендуются для самостоятельного разбора.
Также в рамках лабораторной работы предлагается реализовать функцию вычисления ошибки классификации (долю неправильно классифицированных объектов выборки) getClassificationError:
float getClassificationError(const Mat & samples,
const Mat & classes,
const CvStatModel & model,
int (*predict) (const Mat & sample,
const CvStatModel & model));
Параметры функции:
- samples – признаковые описания объектов выборки.
- classes – номера классов (истинные значения целевого признака) для объектов выборки.
- model – обученная модель.
- predict – указатель на функцию, принимающую один объект выборки и модель и возвращающую номер предсказанного класса.
Данная функция должна вычислять доля неправильно классифицированных объектов выборки.
После того, как описанные функции будут реализованы, предлагается применить рассмотренные алгоритмы классификации к наборам данных из файлов dataset1.yml, dataset2.yml, dataset3.yml, dataset4.yml, datasetMulticlass.yml и datasetHighDim.yml. А также проанализировать, на каких данных лучше/хуже работает тот или иной подход и какое влияние на конечную модель оказывают параметры алгоритма обучения.
Александра Максимова
Алена Борисова
|
В лекции по обработке полутоновых изображений (http://www.intuit.ru/studies/courses/10621/1105/lecture/17979?page=2) увидела следующий фильтр:
В описании говорится, что он "делает изображение более чётким, потому что, как видно из конструкции фильтра, в однородных частях изображение не изменяется, а в местах изменения яркости это изменение усиливается". Что вижу я в конструкции фильтра (скорее всего ошибочно): F(x, y) = 2 * I(x, y) - 1/9 I(x, y) = 17/9 * I(x, y), где F(x, y) - яркость отфильтрованного пикселя, а I(x, y) - яркость исходного пикселя с координатами (x, y). Что означает обычное повышение яркости изображения, при этом без учета соседних пикселей (так как их множители равны 0). Объясните, пожалуйста, как данный фильтр может повышать четкость изображения? |
